黑马头条(4)
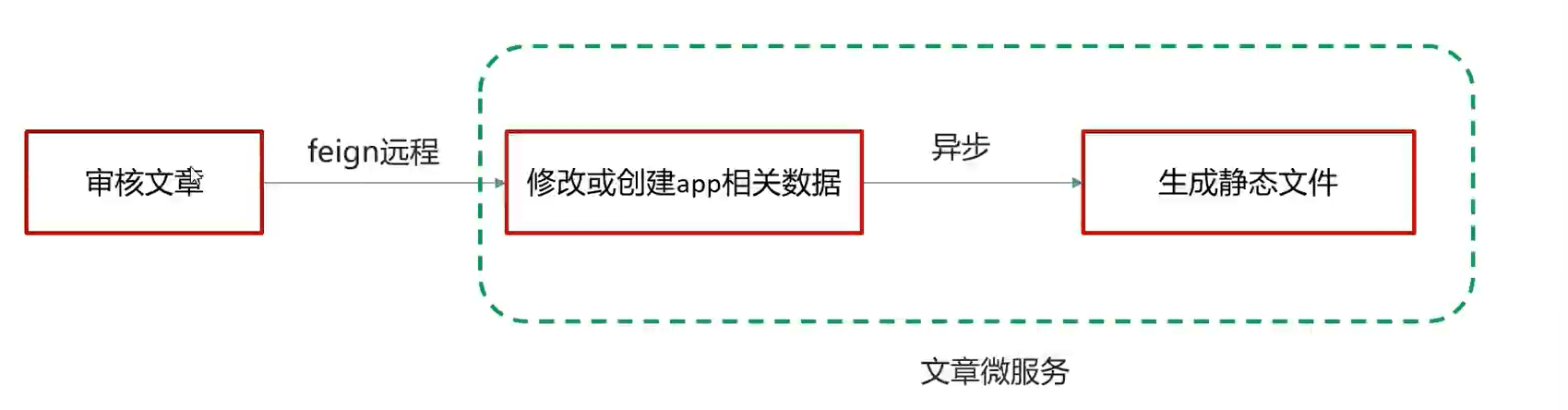
自媒体文章审核
文章数据流
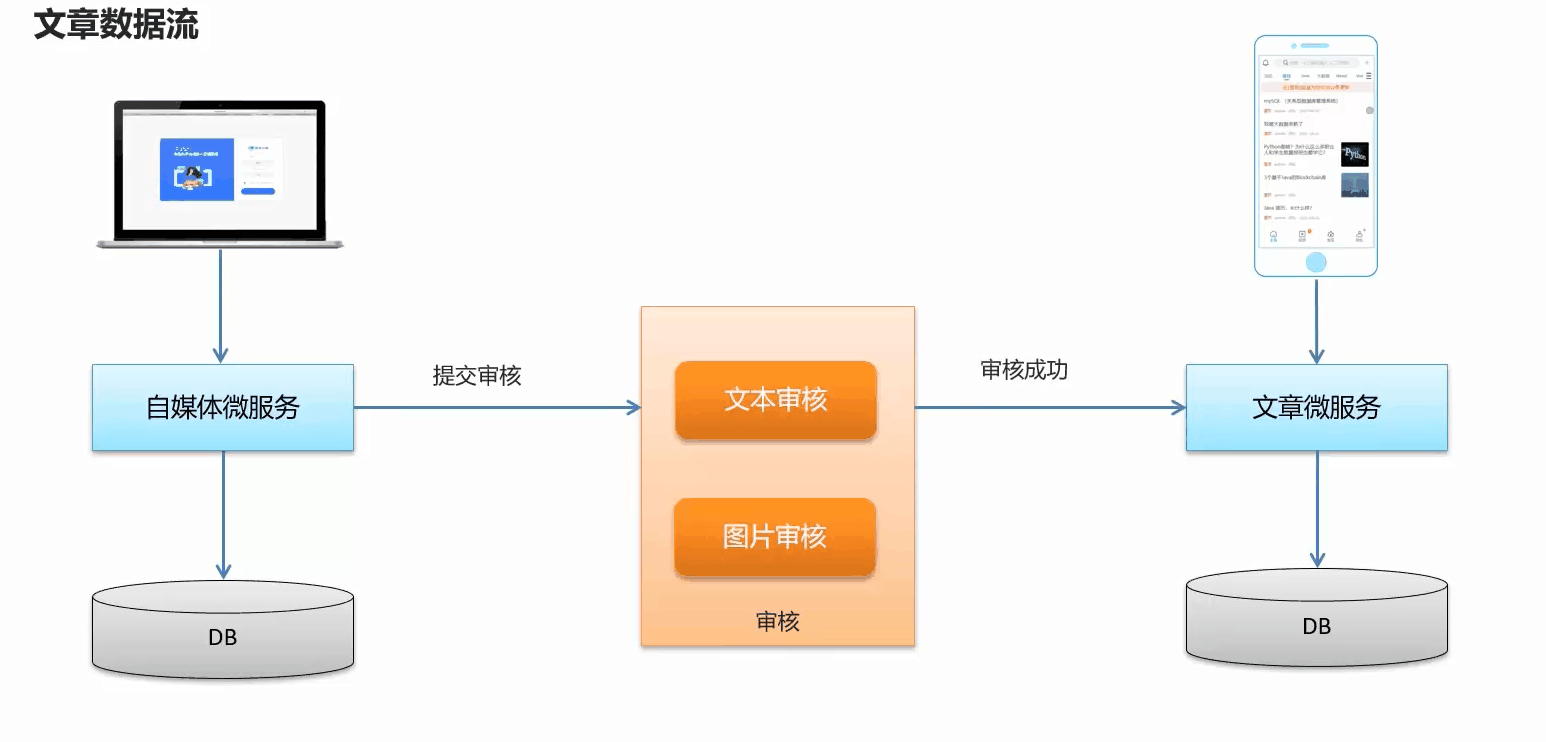

审核方式
- 自动审核
文章发布之后,系统自动审核,主要是通过第三方接口对文章的内容进行审核(成功、失败、不确定)
- 人工审核
待自动审核返回不确定信息时,转到人工审核,由平台管理员进行审核
审核流程图:
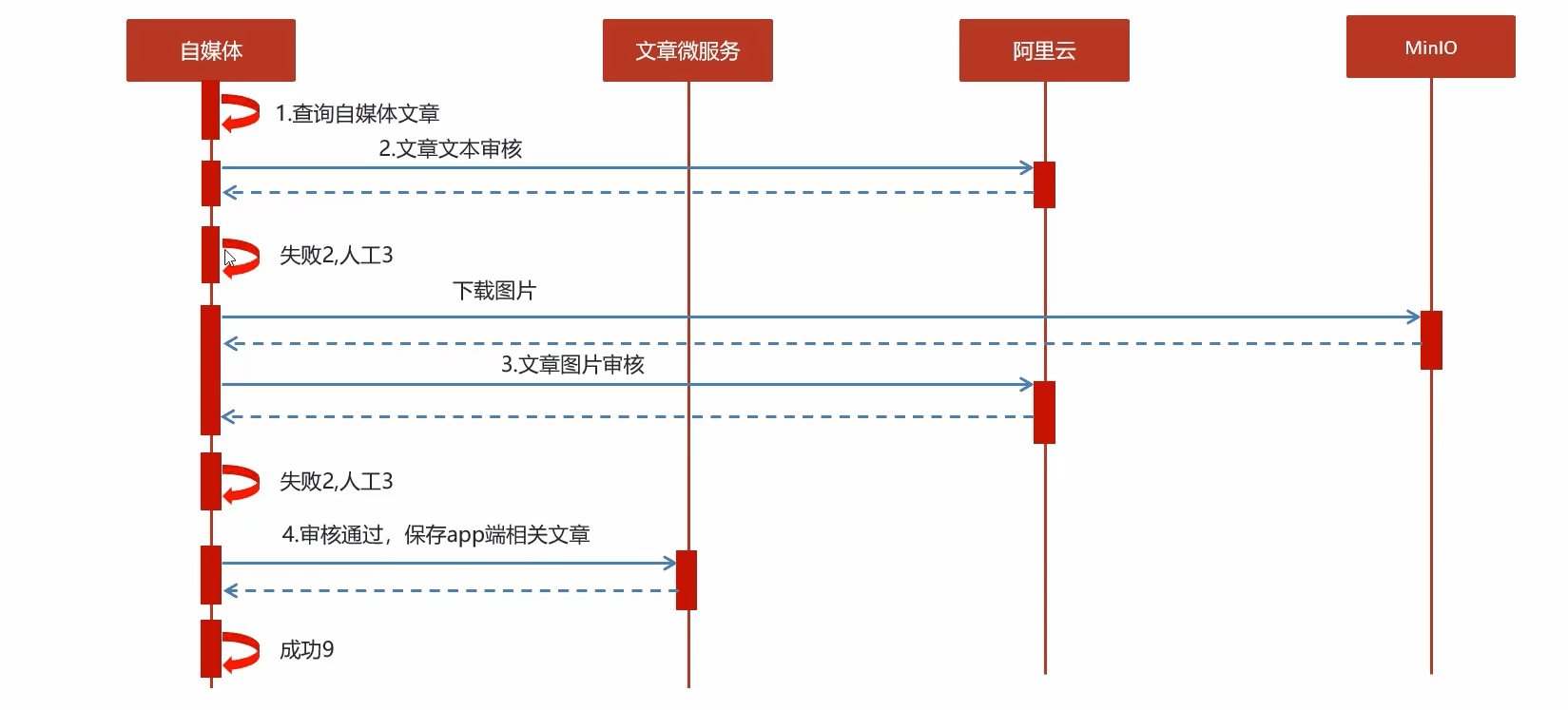
内容安全第三方接口
内容安全接口类型
通过aliyun服务检测内容安全
分布式id
随着业务增长,文章表占用很大物理存储空间,为了解决该问题,后期使用数据库分片技术,将一个数据库进行拆分,通过数据库中间件连接。如果数据库中该表选用ID自增策略,则可能产生重复的ID,此时应该使用分布式ID生成策略来生成ID。
唯一主键生成方案比较
| 方案 | 优势 | 劣势 |
|---|---|---|
| Redis | (INCR)生成一个全局连续递增的数字类型主键 | 增加了一个外部组件的依赖,Redis不可用,则整个数据库将无法插入 |
| UUID | 全局唯一,MySQL也有UUID实现 | 36个字符组成,占用空间大 |
| Snowflake算法 | 全局唯一,数字类型,存储成本低 | 机器规模大于1024台无法支持 |
雪花算法
snowflake是Twitter开源的分布式ID生成算法,结果是一个long型的ID。其核心思想是:使用41bit作为毫秒数,10bit作为机器的ID(5个bit是数据中心,5个bit是机器ID),12bit作为毫秒内的流水号(意味着每个节点在每毫秒可以产生4096个ID),最后还有一个符号位,永远是0。

feign远程调用服务降级处理
- 服务降级是服务自我保护的一种方式,或者保护下流服务的一种方式,用于确保服务不会受请求突增影响变得不可用,确保服务不会崩溃。
- 服务降级虽然会导致请求失败,但是不会导致阻塞
自管理敏感词过滤
需要自己维护一套敏感词,在文章审核的时候,需要验证文章是否包含这些敏感词
| 方案 | 说明 |
|---|---|
| 数据库模糊查询 | 效率太低 |
| String.indexOf("") | 数据库量大的话也是比较慢 |
| 全文检索 | 分词再匹配 |
| DFA算法 | 确定有穷自动机(一种数据结构) |
DFA实现原理
DFA : Deterministic Finite Automation,确定有穷自动机
存储:一次性的把所有的敏感词存储到了多个map中,就是下图的结构
1、创建敏感词表
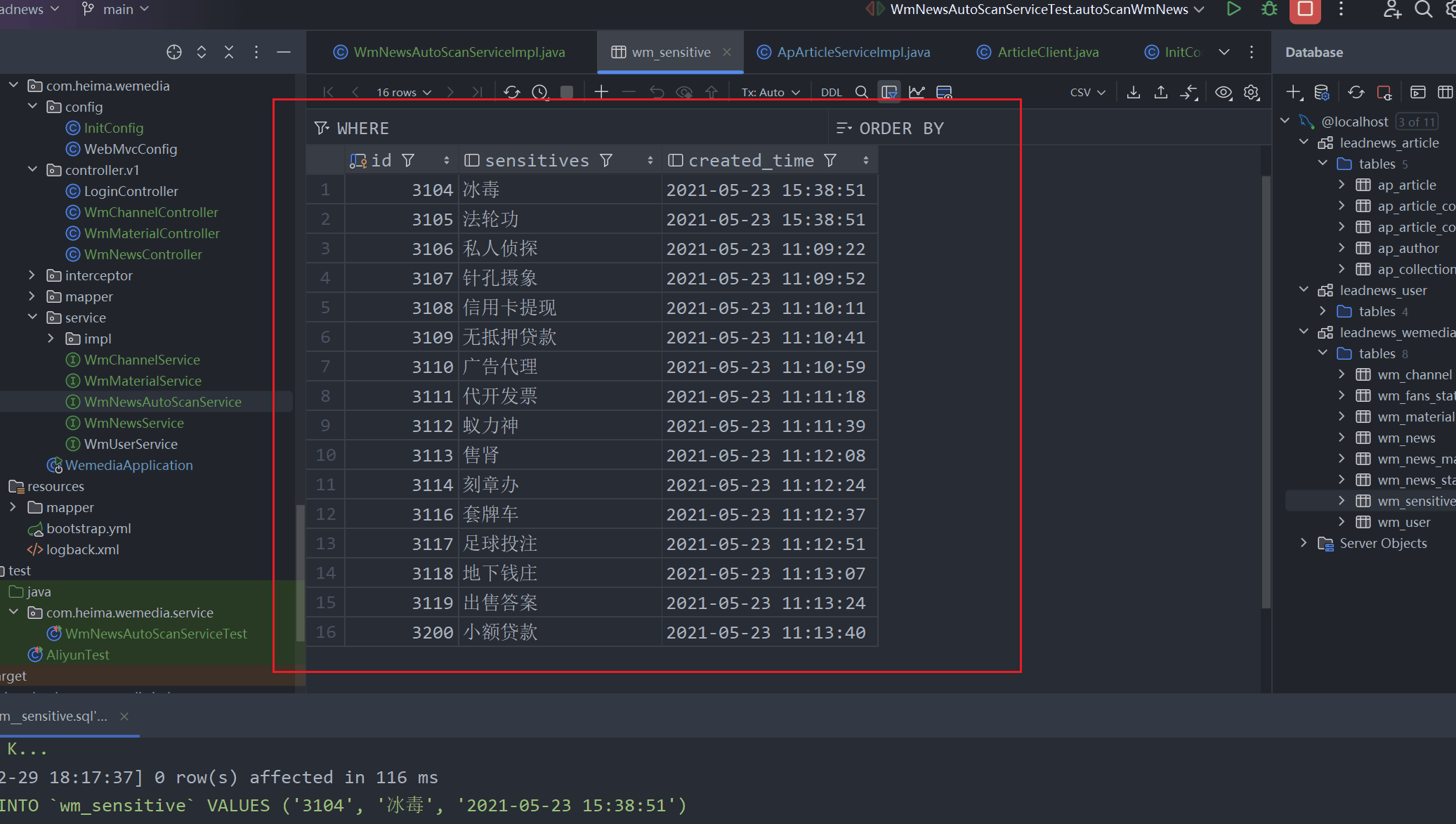
2、敏感词识别工具类
public class SensitiveWordUtil {
public static Map<String, Object> dictionaryMap = new HashMap<>();
/**
* 生成关键词字典库
* @param words
* @return
*/
public static void initMap(Collection<String> words) {
if (words == null) {
System.out.println("敏感词列表不能为空");
return ;
}
// map初始长度words.size(),整个字典库的入口字数(小于words.size(),因为不同的词可能会有相同的首字)
Map<String, Object> map = new HashMap<>(words.size());
// 遍历过程中当前层次的数据
Map<String, Object> curMap = null;
Iterator<String> iterator = words.iterator();
while (iterator.hasNext()) {
String word = iterator.next();
curMap = map;
int len = word.length();
for (int i =0; i < len; i++) {
// 遍历每个词的字
String key = String.valueOf(word.charAt(i));
// 当前字在当前层是否存在, 不存在则新建, 当前层数据指向下一个节点, 继续判断是否存在数据
Map<String, Object> wordMap = (Map<String, Object>) curMap.get(key);
if (wordMap == null) {
// 每个节点存在两个数据: 下一个节点和isEnd(是否结束标志)
wordMap = new HashMap<>(2);
wordMap.put("isEnd", "0");
curMap.put(key, wordMap);
}
curMap = wordMap;
// 如果当前字是词的最后一个字,则将isEnd标志置1
if (i == len -1) {
curMap.put("isEnd", "1");
}
}
}
dictionaryMap = map;
}
/**
* 搜索文本中某个文字是否匹配关键词
* @param text
* @param beginIndex
* @return
*/
private static int checkWord(String text, int beginIndex) {
if (dictionaryMap == null) {
throw new RuntimeException("字典不能为空");
}
boolean isEnd = false;
int wordLength = 0;
Map<String, Object> curMap = dictionaryMap;
int len = text.length();
// 从文本的第beginIndex开始匹配
for (int i = beginIndex; i < len; i++) {
String key = String.valueOf(text.charAt(i));
// 获取当前key的下一个节点
curMap = (Map<String, Object>) curMap.get(key);
if (curMap == null) {
break;
} else {
wordLength ++;
if ("1".equals(curMap.get("isEnd"))) {
isEnd = true;
}
}
}
if (!isEnd) {
wordLength = 0;
}
return wordLength;
}
/**
* 获取匹配的关键词和命中次数
* @param text
* @return
*/
public static Map<String, Integer> matchWords(String text) {
Map<String, Integer> wordMap = new HashMap<>();
int len = text.length();
for (int i = 0; i < len; i++) {
int wordLength = checkWord(text, i);
if (wordLength > 0) {
String word = text.substring(i, i + wordLength);
// 添加关键词匹配次数
if (wordMap.containsKey(word)) {
wordMap.put(word, wordMap.get(word) + 1);
} else {
wordMap.put(word, 1);
}
i += wordLength - 1;
}
}
return wordMap;
}
public static void main(String[] args) {
List<String> list = new ArrayList<>();
list.add("法轮");
list.add("法轮功");
list.add("冰毒");
initMap(list);
String content="我是一个好人,并不会卖冰毒,也不操练法轮功,我真的不卖冰毒";
Map<String, Integer> map = matchWords(content);
System.out.println(map);
}
}
3、添加对应的敏感词过滤逻辑
/**
* 自管理敏感词审核
* @param content
* @param wmNews
* @return
*/
private boolean handelSensitiveScan(String content, WmNews wmNews) {
boolean flag = true;
// 获取所有的敏感词
List<WmSensitive> wmSensitives = wmSensitiveMapper.selectList(Wrappers.<WmSensitive>lambdaQuery().select(WmSensitive::getSensitives));
List<String> collectList = wmSensitives.stream().map(WmSensitive::getSensitives).collect(Collectors.toList());
// 初始化敏感词库
SensitiveWordUtil.initMap(collectList);
// 查看文章中是否包含敏感词
Map<String, Integer> map = SensitiveWordUtil.matchWords(content);
if (!map.isEmpty()){
updateWmNews(wmNews, WmNews.Status.FAIL, "当前文章中存在违规内容" + map);
flag = false;
}
return flag;
}
图片文字-敏感词过滤
图片文字识别
OCR(Optical Character Recognition,光学字符识别)是指电子设备检查纸上的字符,通过检测暗、亮的模式确定其形状,然后用字符识别的方法将形状翻译成计算机文字的过程。
Tesseract - OCR
导入依赖:
<dependency>
<groupId>net.sourceforge.tess4j</groupId>
<artifactId>tess4j</artifactId>
<version>4.1.1</version>
</dependency>
下载对应的模型
识别
public static void main(String[] args) throws TesseractException {
ITesseract tesseract = new Tesseract();
tesseract.setDatapath("D:\\workspace\\tessdata");
tesseract.setLanguage("chi_sim");
File file = new File("D:\\workspace\\image1.png");
String result = tesseract.doOCR(file);
System.out.println("识别的结果为:\n" + result.replaceAll("[\\r\\n]", "-"));
}
文章详情-静态文件的生成
文章端创建app相关文章时,生成文章详情静态页上传到MinIO中