黑马头条(5)
文章定时发布


延迟任务
DelayQueue
JDK自带 DelayQueue 是一个支持延时获取元素的阻塞队列,内部采用优先队列 PriorityQueue 存储元素,同时元素必须实现Delayed接口;在创建元素时可以指定多久才可以从队列中获取当前元素,只有在延迟期满时才能从队列中提取元素。

使用 DelayQueue 作为延迟任务,如果程序挂掉之后,任务都是放在内存,消息会丢失,如何保证数据不丢失。
RabbitMQ
- TTL : Time To Live (消息存活时间)
- 死信队列:Dead Letter Exchange(死信交换机),当消息成为Dead message后,可以重新发送另一个交换机(死信交换机)
Redis实现
zset数据类型的去重有序(分数排序)特点进行延迟。例如:时间戳(毫秒值)作为score进行排序

Redis实现延迟任务
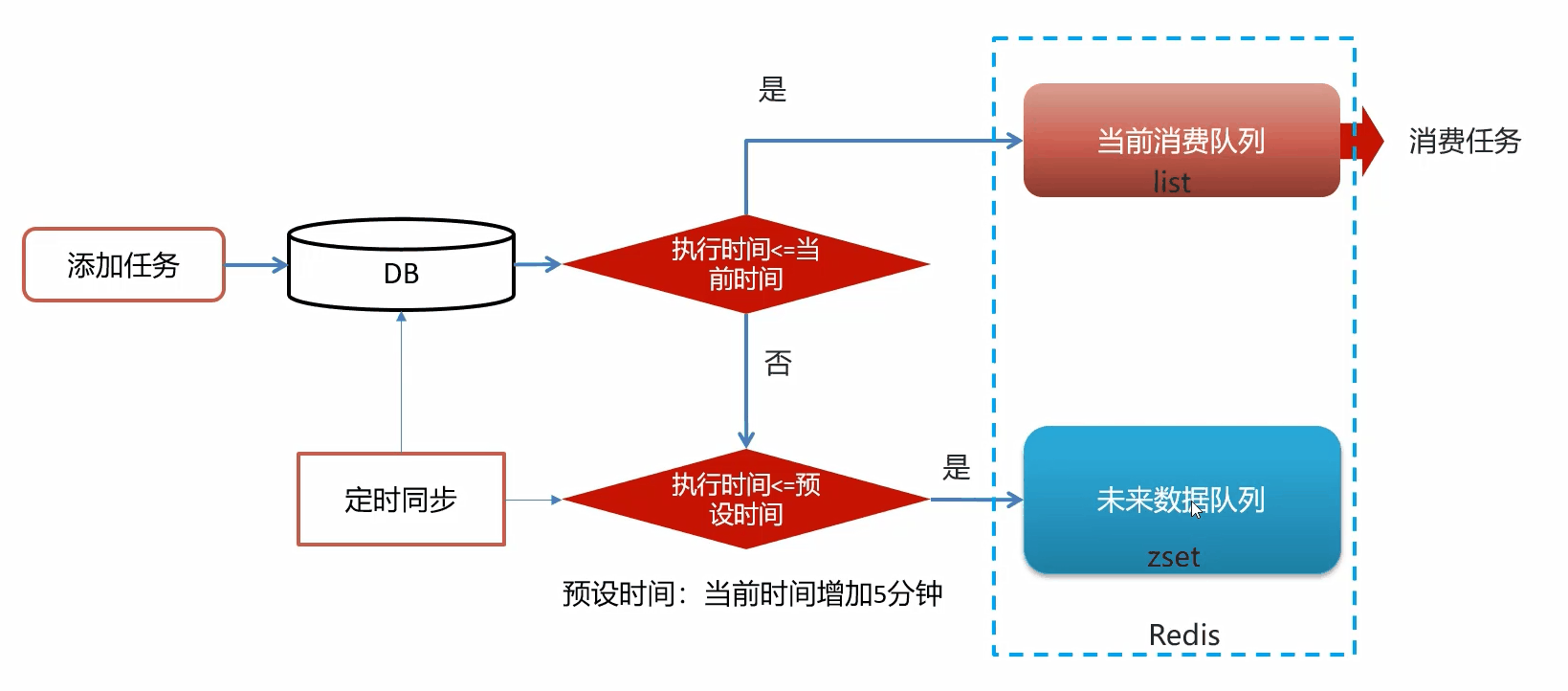
为什么任务需要存储到数据库中?
延迟任务是一个通用的服务,任何有延迟需求的任务都可以调用该服务,内存数据库的存储是有限的,需要考虑数据持久化的问题,存储数据库中的一种数据安全的考虑。
为什么要使用redis中的两种数据类型,list和zset?
原因一:list存储立即执行的任务,zset存储未来的数据
原因二:任务量过大以后,zset的性能会下降
- 操作
redis中的list命令LPUSH:时间复杂度 $O(1)$ - 操作
redis中的zset命令zadd:时间复杂度 $O(M * log(n))$
添加zset数据时,为什么需要预加载?
如果任务数据特别大,为了防止阻塞,只需要把未来几分钟要执行的数据存入缓存即可,是一种优化方式。
延迟任务的实现
数据库准备-数据库自身解决并发两种策略
- 悲观锁(Pessimistic Lock)
每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁。
- 乐观锁(Optimistic Lock)
每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据,可以使用版本号等机制
数据库准备 - mybatis-plus集成乐观锁的使用
1、在实体类中使用 @Version 标明是一个版本的字段
/**
* 版本号,用乐观锁
*/
@Version
private Integer version;
2、mybatis-plus对乐观锁的支持,在启动类中向容器中放入乐观锁的拦截器
/**
* mybatis-plus乐观锁支持
* @return
*/
@Bean
public MybatisPlusInterceptor optimisticLockerInterceptor(){
MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor();
interceptor.addInnerInterceptor(new OptimisticLockerInnerInterceptor());
return interceptor;
}
Redis环境搭建
1、拉取镜像
docker pull redis
2、创建容器
# 使用docker命令运行一个新的容器实例
docker run \
# -d: 以分离模式(后台)运行容器
-d \
# --name redis: 给容器指定一个名称为 "redis"
--name redis \
# --restart=always: 容器在停止后总是重启,适用于需要持续运行的服务
--restart=always \
# --p 6379:6379: 将主机的6379端口映射到容器的6379端口
# 注意:应为 --publish 而非 --p
--publish 6379:6379 \
# redis: 使用官方Redis镜像
redis \
# --requirepass "leadnews": 设置Redis的访问密码为 "leadnews"
--requirepass "leadnews"
添加工具类CacheService.java ,然后测试工具类:
@SpringBootTest
@RunWith(SpringRunner.class)
public class RedisTest {
@Autowired
private CacheService cacheService;
@Test
public void testList(){
// 在list的左边添加元素
cacheService.lLeftPush("list_001", "hello, redis");
// 在list的右边获取元素,并删除
String s = cacheService.lRightPop("list_001");
System.out.println(s);
}
@Test
public void testZset(){
// 添加元素到zset中
// cacheService.zAdd("zset_001", "zset_001_1", 1000);
// cacheService.zAdd("zset_001", "zset_001_2", 888);
// cacheService.zAdd("zset_001", "zset_001_3", 777);
// cacheService.zAdd("zset_001", "zset_001_4", 999999);
// 按照分值获取数据
Set<String> zset001 = cacheService.zRangeByScore("zset_001", 0, 1000);
System.out.println(zset001);
}
}
取消任务
场景:第三接口网络不通,使用延迟任务进行重试,当达到阈值以后,取消任务
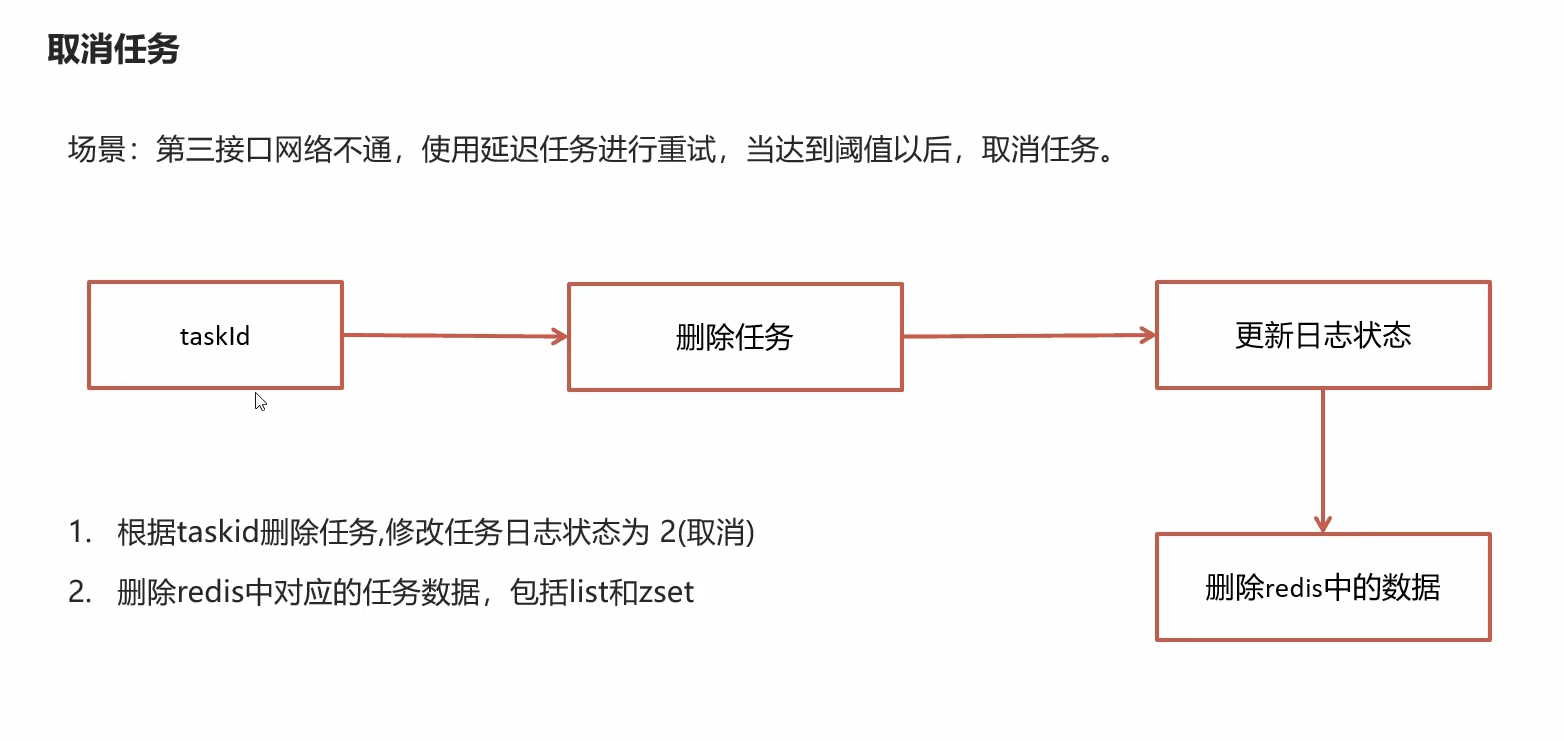
消费任务

未来数据定时刷新-redis key值匹配
方案一:keys 模糊匹配
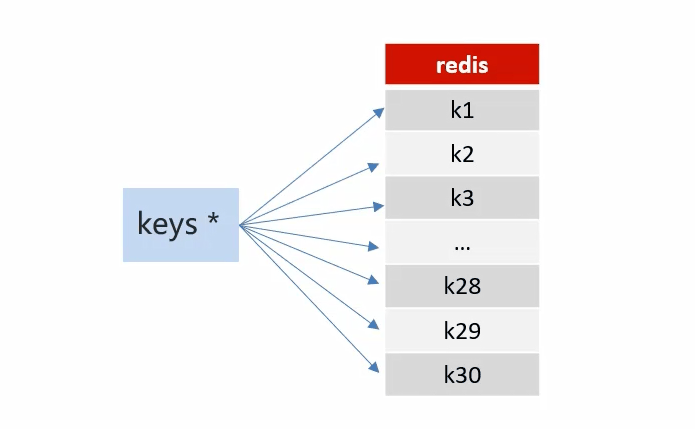
Redis CPU 占用高,且redis是单线程,会被阻塞。
方案二:scan
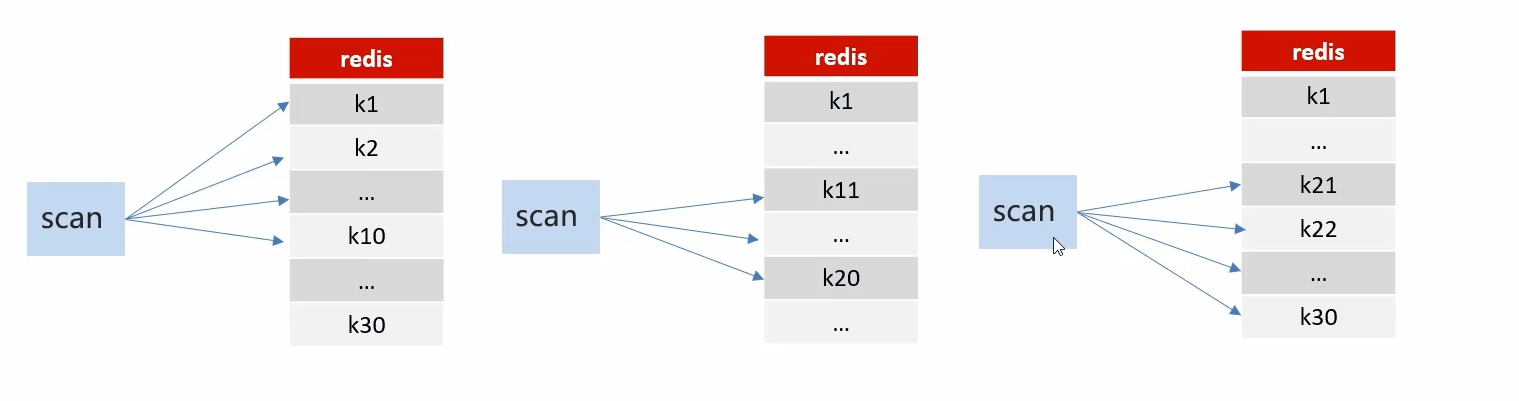
基于游标的迭代器,每次被调用会返回新游标,用户在下一次使用这个新游标作为SCAN命令的游标参数,以此来延续之前的迭代过程。
用管道的方式存入数据
// 耗时6554
@Test
public void testPiple1() {
long start = System.currentTimeMillis();
for (int i = 0; i < 10000; i++) {
Task task = new Task();
task.setTaskType(1001);
task.setPriority(1);
task.setExecuteTime(new Date().getTime());
cacheService.lLeftPush("1001_1", JSON.toJSONString(task));
}
System.out.println("耗时" + (System.currentTimeMillis() - start));
}
// 使用管道技术执行10000次自增操作共耗时:1414毫秒
@Test
public void testPiple2() {
long start = System.currentTimeMillis();
//使用管道技术
List<Object> objectList = cacheService.getstringRedisTemplate().executePipelined(new RedisCallback<Object>() {
@Nullable
@Override
public Object doInRedis(RedisConnection redisConnection) throws DataAccessException {
for (int i = 0; i < 10000; i++) {
Task task = new Task();
task.setTaskType(1001);
task.setPriority(1);
task.setExecuteTime(new Date().getTime());
redisConnection.lPush("1001_1".getBytes(), JSON.toJSONString(task).getBytes());
}
return null;
}
});
System.out.println("使用管道技术执行10000次自增操作共耗时:" + (System.currentTimeMillis() - start) + "毫秒");
}
实现步骤
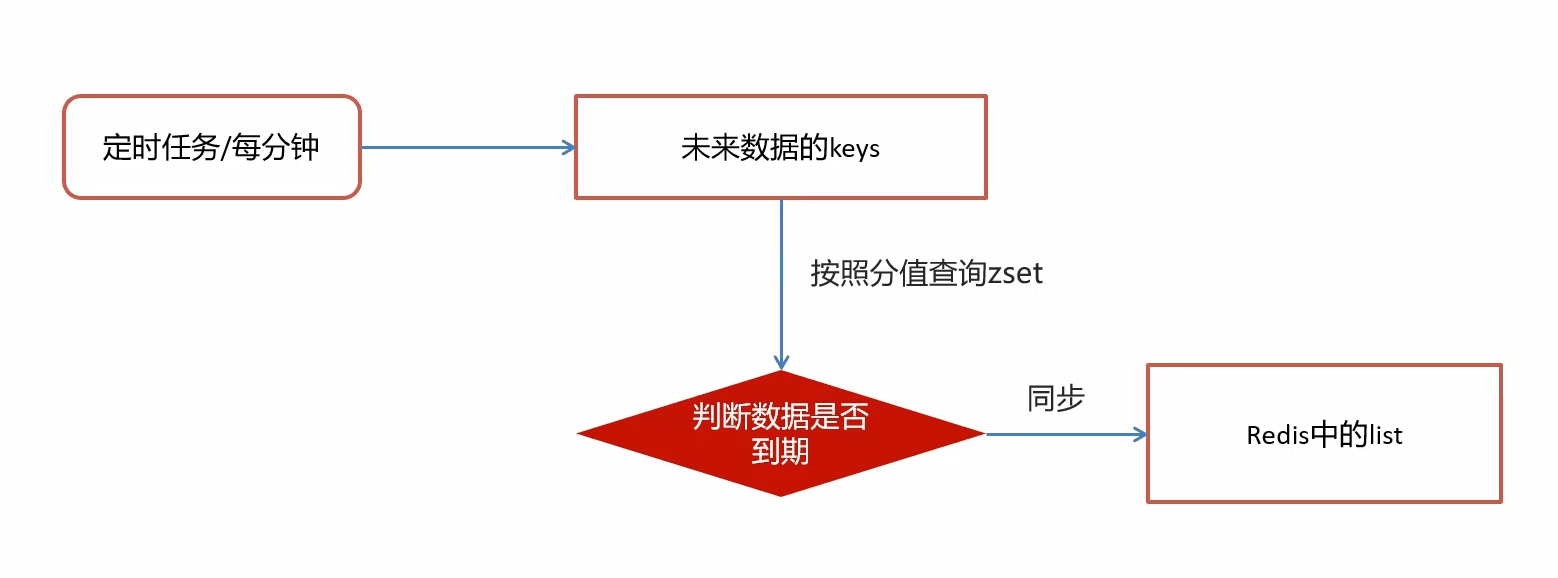
延迟队列服务
分布式锁解决集群下的方法抢占执行
分布式锁
控制分布式系统有序的对共享资源进行操作,通过互斥来保证数据的一致性
分布式锁的解决方案:
| 方案 | 说明 |
|---|---|
| 数据库 | 基于表的唯一索引 |
| zookeeper | 根据zookeeper中的临时有序节点排序 |
| redis | 使用SETNX命令完成 |
SETNX
(SET if Not eXists) 命令在指定的key不存在时,为key设置指定的值
/**
* 加锁
*
* @param name
* @param expire
* @return
*/
public String tryLock(String name, long expire) {
name = name + "_lock";
String token = UUID.randomUUID().toString();
RedisConnectionFactory factory = stringRedisTemplate.getConnectionFactory();
RedisConnection conn = factory.getConnection();
try {
//参考redis命令:
//set key value [EX seconds] [PX milliseconds] [NX|XX]
Boolean result = conn.set(
name.getBytes(),
token.getBytes(),
Expiration.from(expire, TimeUnit.MILLISECONDS),
RedisStringCommands.SetOption.SET_IF_ABSENT //NX
);
if (result != null && result)
return token;
} finally {
RedisConnectionUtils.releaseConnection(conn, factory, false);
}
return null;
}
发布文章集成添加延迟队列接口
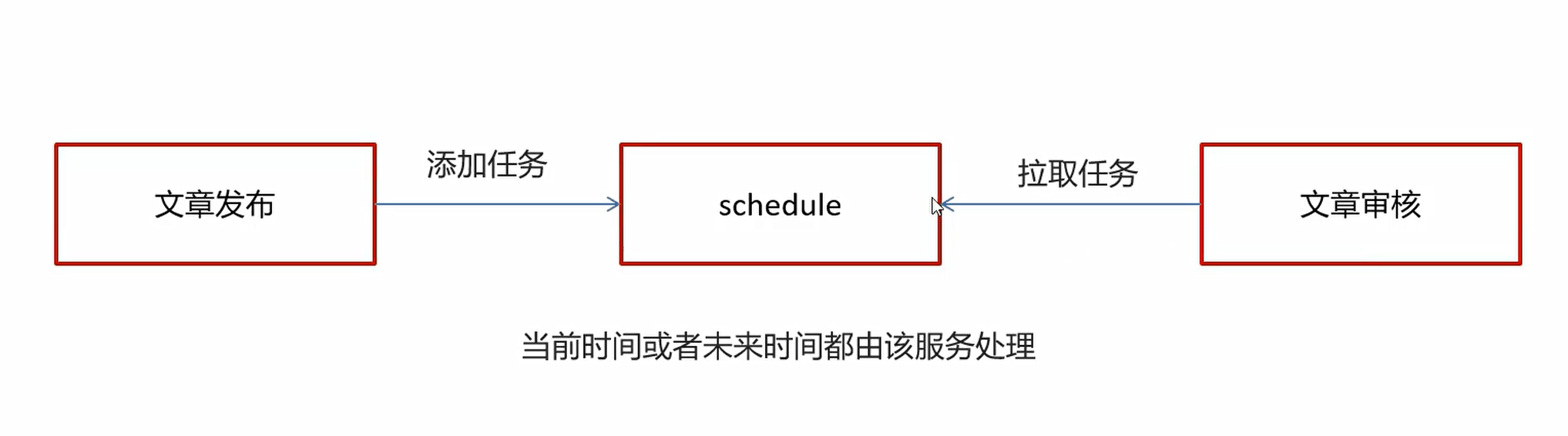
序列化工具对比
JdkSerialize: Java内置的序列化能将实现了Serilazable接口的对象进行序列化和反序列化,ObjectOutputStream的writeObject()方法可序列化对象生成字节数组Protostuff:google开源的Protostuff采用更为紧凑的二进制数组,表现更加优异,然后使用Protostuff的编译工具生成pojo类