机器学习简介
Different types of Functions
Regression : The function outputs a scalar(标量).
- predict the PM2.5
Classification : Given options (classes), the function outputs the correct one.
- Spam filtering
Structured Learning : create something with structure(image, document)
Example : YouTube Channel
1.Function with Unknown Parameters.
$$ y=b+wx_1 $$
2.Define Loss from Training Data
- Loss is a function of parameters
$$ L(b,w) $$
- Loss : how good a set of values is.
- L is mean absolute error (MAE)
$$ e=\left | y-\hat{y} \right | $$
- L is mean square error (MSE)
$$ e=(y-\hat{y})^2 $$
$$ L=\frac{1}{N} \sum_{n}^{}e_n $$
3.Optimization
$$ w^,b^=arg,\min_{w,b} ,L $$
Gradient Descent
- (Randomly) Pick an initial value :
$$ w^0 $$
- Compute :
$$ \frac {\partial L} {\partial w} |_{w=w_0} $$
Negative : Increase w
Positive : Decrease w
$$ \eta\frac {\partial L} {\partial w} |_{w=w_0} $$
η:learning rate (hyperparameters)
- Update w iteratively
- Local minima
- global minima
类似一个参数,推广到多个参数。
Linear Models
Linear models have severe limitation. Model Bias.
We need a more flexible model!
curve = constant + sum of a set of Hard Sigmoid Function
$$ y=c\frac {1} {1+exp(-(b+wx_1))} \ =csigmoid(b+wx_1) $$
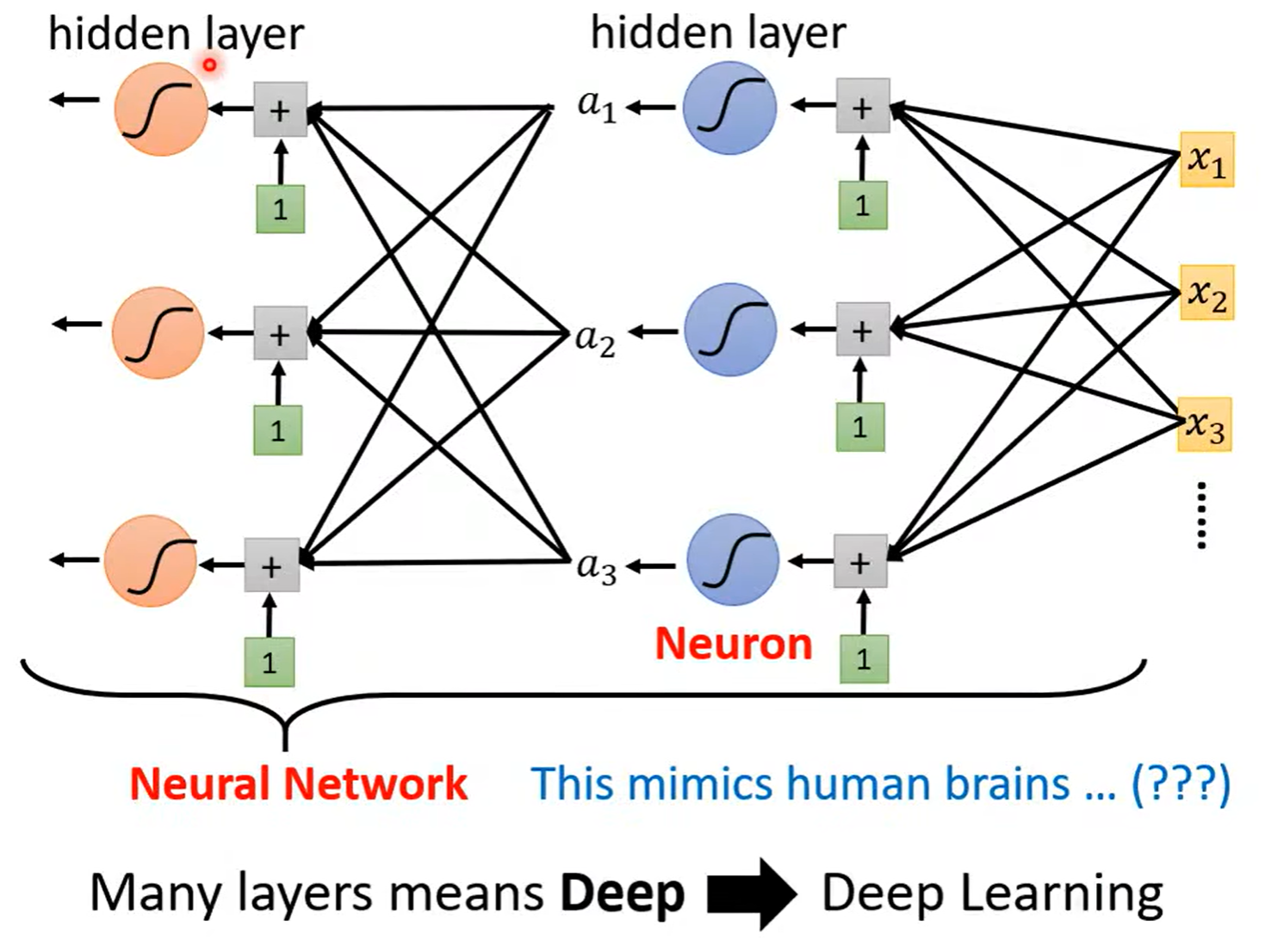
$$ y=b+\sum_{i}sigmoid(b_i+w_ix_i) $$
$$ y=b+\sum_{i}sigmoid(b_i+\sum_{j}w_{ij}x_j) $$
线性代数角度:
$$ r=b+Wx $$
$$ a=\sigma(r) $$
$$ y=b+c^Ta $$
Loss
- Loss is a function of parameters L(θ)
- Loss means how good a set of values is.
Optimization of New Model
$$
\theta=
\begin{bmatrix}
\theta_1 \
\theta_2 \
\theta_3 \
\dots
\end{bmatrix}
$$
$$ \theta=arg \min_\theta L $$
- (Randomly) Pick initial values θ^0
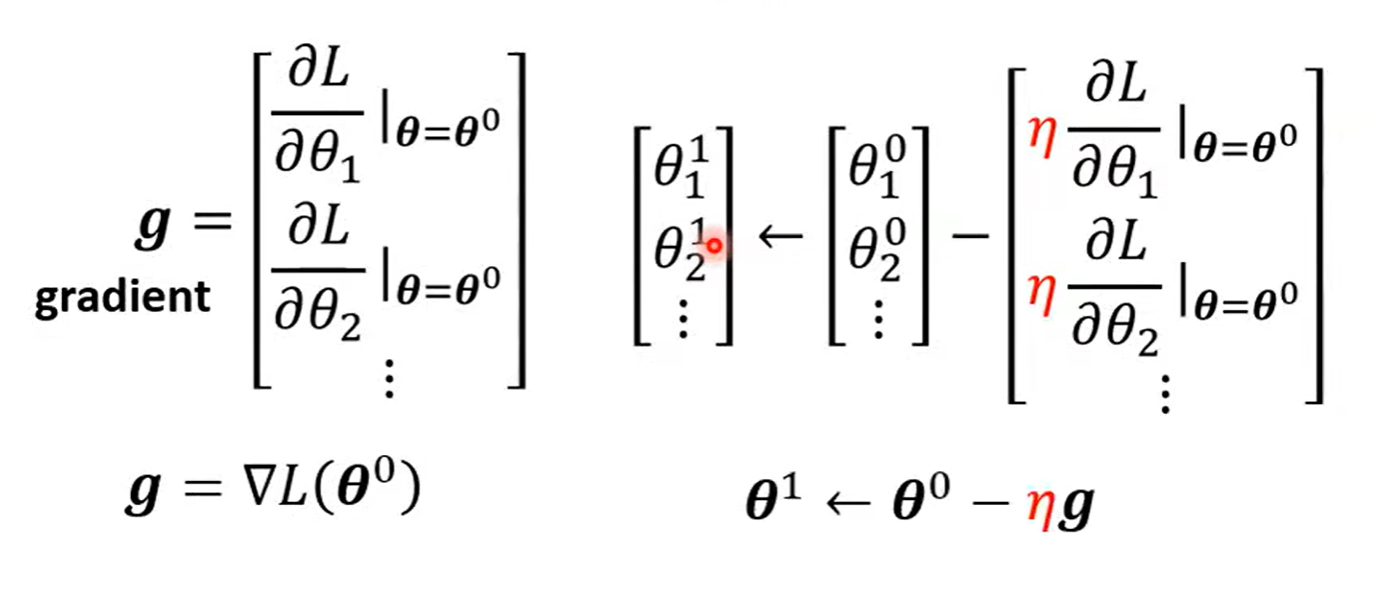
1 epoch = see all the batched once
update : update θ for each batch
Sigmoid -> ReLU (Rectified Linear Unit)
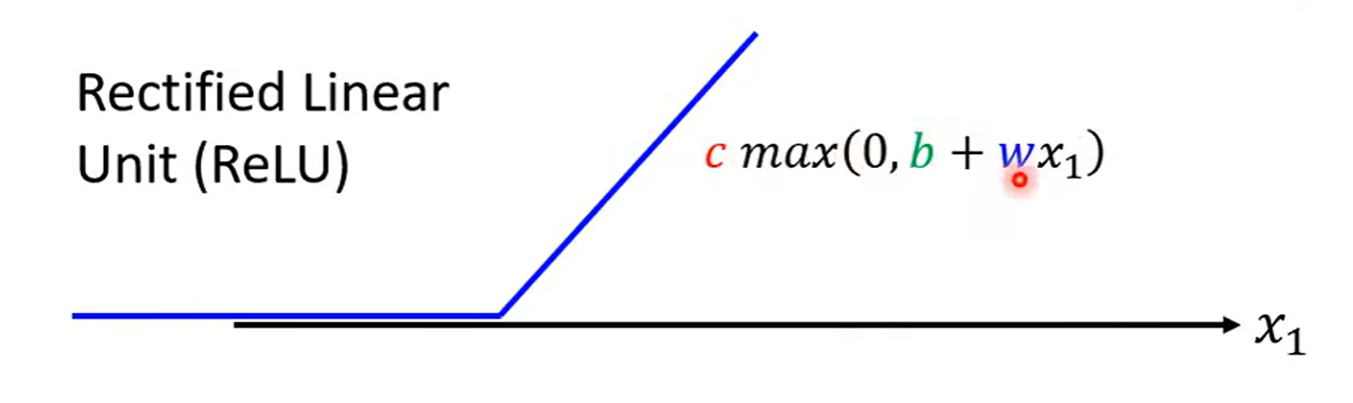
统称为 Activation function
Neural Network