Spatial Transformer(STN)
处理旋转和放大图形的CNN分类
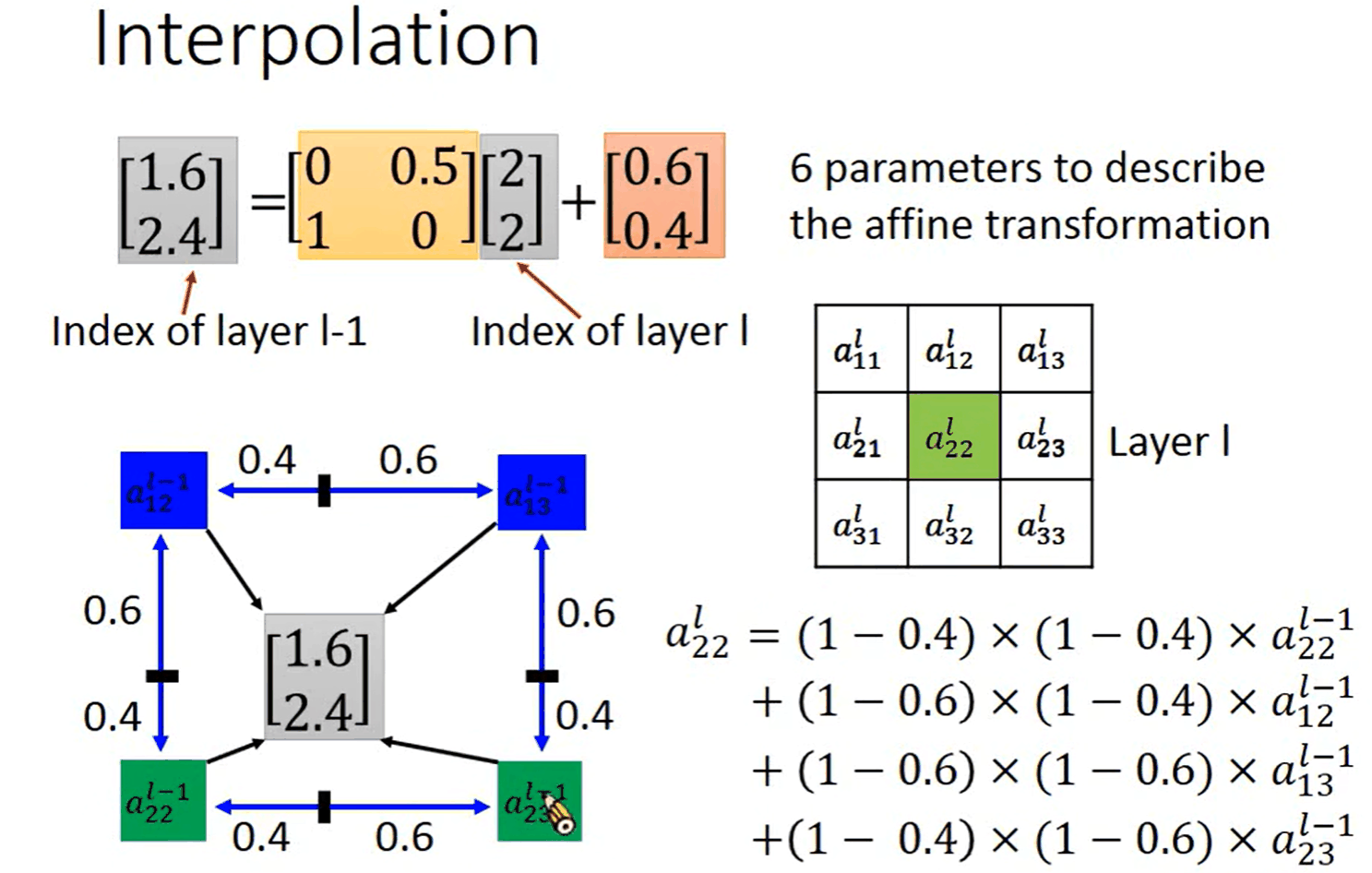
interpolation 插值法
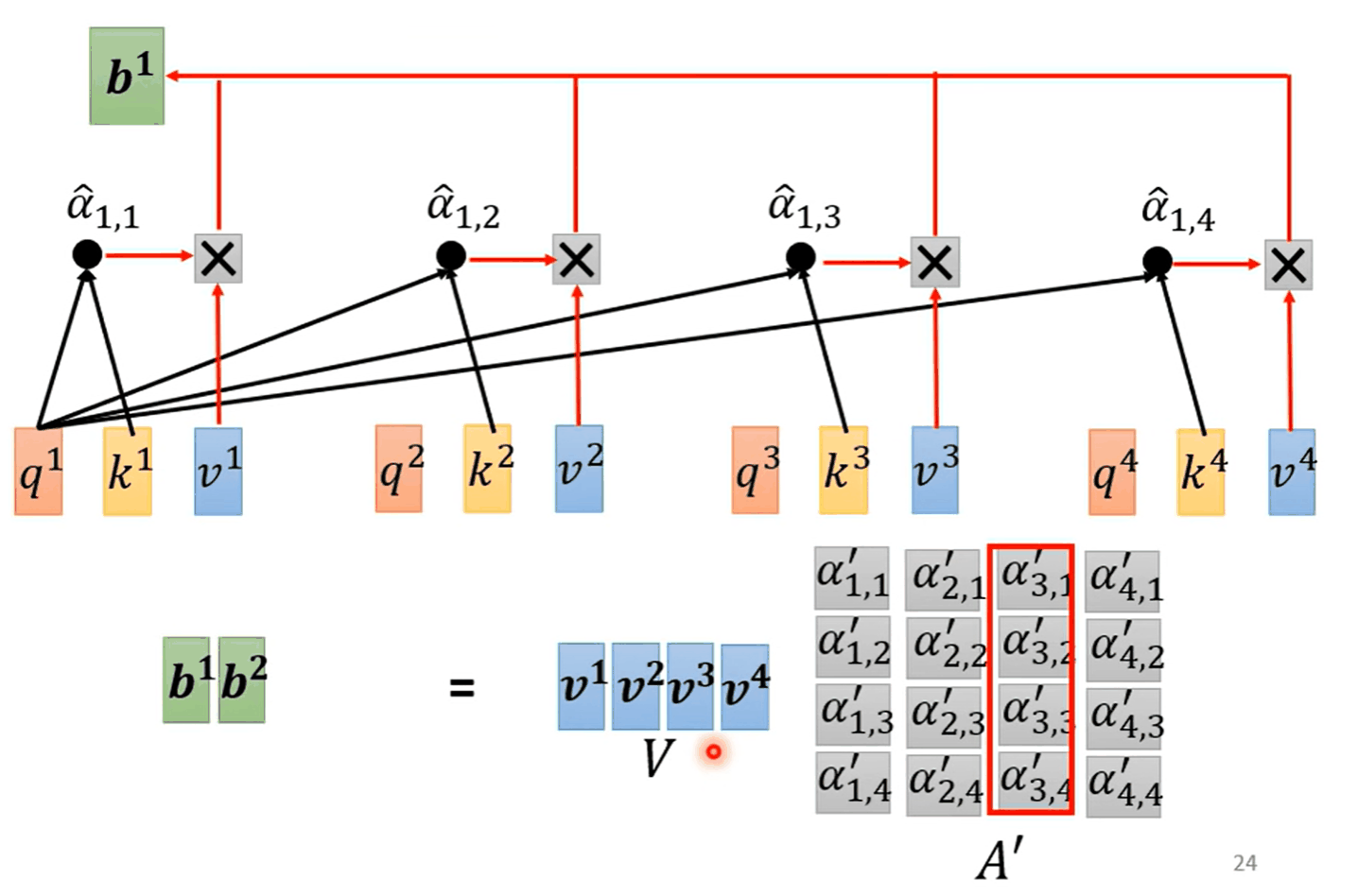
Self-attention
Sequence Labeling
consider the context -> 参数很大并且容易Over fitting
Self-attention会持有整个sequence的信息
input : vector
output : vector $$ q_i=W^qa^i\ k_i=W^ka^i\ v^i=W^va^i $$
Multi-head Self-attention
其中 $$ q_i, k_i, v_i均可以有多个 $$
Self-attention for Speech
Truncated(截短的) Self-attention
Self-attention is the complex version of CNN
CNN is simplified self-attention
- Recurrent Neural Network(RNN)
RNN所做的事情都可以用Self-attention来替代
Self-attention更有效率
RNN
Transformer
Sequence to sequence (Seq2seq)
Encoder -> Decoder
Encoder
input some vectors and output some vectors
Decoder
Autoregressive
Non-autoregressive Decoder
同时输出BEGIN并且同时输出结果和END
Advantage : parallel, controllable output length
NAT is usually worse than AT
Encoder-Decoder
Cross Attention
Teacher Forcing : using the ground truth as input
Copy Mechanism
- Pointer Network
- Copying Mechanism
Guided Attention
Beam Search
Scheduled Sampling