MIT6.S081(13)-Coordination (sleep&wakeup)
plan
Re-emphasize a few points about xv6 thread switching sequence coordination sleep & wakeup lost wakeup problem termination
Why hold p->lock across swtch()?
this is an important point and affects many situations in xv6 [diagram: P1, STACK1, swtch, STACK_SCHED] yield:
acquire(&p->lock);
p->state = RUNNABLE;
swtch();
scheduler:
swtch();
release(&p->lock);
the main point of holding p->lock across swtch():
prevent another core’s scheduler from seeing p->state == RUNNABLE
until after the original core has stopped executing the thread
and after the original core has stopped using the thread’s stack
Why does sched() forbid spinlocks from being held when yielding the CPU?
(other than p->lock)
i.e. sched() checks that noff == 1
on a single-core machine, imagine this:
P1 P2
acq(L)
sched()
acq(L)
this is a deadlock: P2 will spin until P1 releases – and P2 won’t yield the CPU but P1 won’t release until it runs again with multiple cores, deadlock can also arise; more spinlocks must be involved solution: do not hold spinlocks and yield the CPU!
topic: sequence coordination
threads need to wait for specific events or conditions: wait for disk read to complete (event is from an interrupt) wait for pipe writer to produce data (event is from a thread) wait for any child to exit
coordination is a fundamental building-block for thread programming.
often straightforward to use. but (like locks) subject to rules that sometimes present difficult puzzles.
why not just have a while-loop that spins until event happens?
pipe read:
while buffer is empty {
}
pipe write:
put data in buffer
better solution: coordination primitives that yield the CPU
there are a bunch e.g. barriers, semaphores, event queues.
xv6 uses sleep & wakeup
example: uartwrite() and uartintr() in uart.c
I have modified these functions!
not the same as default xv6
see “code” link on schedule page
the basic idea:
the UART can only accept one (really a few) bytes of output at a time
takes a long time to send each byte, perhaps millisecond
processes writing the console must wait until UART sends prev char
the UART interrupts after it has sent each character
writing thread should give up the CPU until then
write() calls uartwrite()
uartwrite() writes first byte (if it can)
uartwrite() calls sleep() to wait for the UART’s interrupt
uartintr() calls wakeup()
the “&tx_chan” argument serves to link the sleep and wakeup
simple and flexible:
sleep/wakeup don’t need to understand what you’re waiting for
no need to allocate explicit coordination objects
Why the lock argument to sleep()?
sadly you cannot design sleep() as cleanly as you might hope
sleep() cannot simply be “wait for this event”
the problem is called “lost wakeups”
it lurks behind all sequence coordination schemes, and is a pain
here’s the story
suppose just sleep(chan); how would we implement?
here’s a BROKEN sleep/wakeup
broken_sleep(chan)
sleeps on a “channel”, a number/address
identifies the condition/event we are waiting for
p->state = SLEEPING;
p->chan = chan;
sched();
wakeup(chan)
wakeup wakes up all threads sleeping on chan may wake up more than one thread
for each p:
if p->state == SLEEPING && p->chan == chan:
p->state = RUNNABLE
how would uart code use this (broken) sleep/wakeup?
int done
uartwrite(buf):
for each char c:
while not done:
sleep(&done)
send c
done = false
uartintr():
done = true
wakeup(&done)
done==true is the condition we're waiting for
&done is the sleep channel (not really related to the condition)
but what about locking?
driver’s data structures e.g. done
UART hardware
both uartwrite() and uartintr() need to lock
should uartwrite() hold a lock for the whole sequence?
no: then uartintr() can’t get lock and set done
maybe uartwrite() could release the lock before sleep()?
let’s try it – modify uart.c to call broken_sleep()
release(&uart_tx_lock);
broken_sleep(&tx_chan);
acquire(&uart_tx_lock);
what goes wrong when uartwrite() releases the lock before broken_sleep()?
uartwrite() saw that the previous character wasn’t yet done being sent
interrupt occurred after release(), before broken_sleep()
uartwrite() went to sleep EVEN THOUGH UART TX WAS DONE
now there is nothing to wake up uartwrite(), it will sleep forever
this is the “lost wakeup” problem.
we need to eliminate the window between uartwrite()’s check of the condition, and sleep() marking the process as asleep. we’ll use locks to prevent wakeup() from running during the entire window.
we’ll change the sleep() interface and the way it’s used. we’ll require that there be a lock that protects the condition, and that the callers of both sleep() and wakeup() hold the “condition lock” sleep(chan, lock) caller must hold lock sleep releases lock, re-acquires before returning wakeup(chan) caller must hold lock (repair uart.c)
let’s look at wakeup(chan) in proc.c
it scans the process table, looking for SLEEPING and chan
it grabs each p->lock
remember also that caller acquired condition lock before calling wakeup()
so wakeup() holds BOTH the condition lock and each p->lock
let’s look at sleep() in proc.c
sleep must release the condition lock
since we can’t hold locks when calling swtch(), other than p->lock
Q: how can sleep() prevent wakeup() from running after it releases the condition lock?
A: acquire p->lock before releasing condition lock
since wakeup() holds both locks, it’s enough for sleep() to hold either
in order to force wakeup() to spin rather than look at this process
now wakeup() can’t proceed until after swtch() completes
so wakeup() is guaranteed to see p->state==SLEEPING and p->chan==chan
thus: no lost wakeups!
note that uartwrite() wraps the sleep() in a loop
i.e. re-checks the condition after sleep() returns, may sleep again
two reasons:
maybe multiple waiters, another thread might have consumed the event
kill() wakes up processes even when condition isn’t true
all uses of sleep are wrapped in a loop, so they re-check
Another example: piperead()
the condition is data waiting to be read (nread != nwrite) pipewrite() calls wakeup() at the end what is the race if piperead() used broken_sleep()? note the the loop around sleep() multiple processes may be reading the same pipe why the wakeup() at the end of piperead()?
the sleep/wakeup interface/rules are a little complex
sleep() doesn’t need to understand the condition, but it needs the condition lock
sleep/wakeup is pretty flexible, though low-level
there are other schemes that are cleaner but perhaps less general-purpose
e.g. the counting semaphore in today’s reading
all have to cope with lost wakeups, one way or another
another coordination challenge – how to terminate a thread?
a puzzle: we want need to free resources that might still be in use
problem: thread X cannot just destroy thread Y
what if Y is executing on another core? what if Y holds locks? what if Y is in the middle of a complex update to important data structures?
problem: a thread cannot free all of its own resources
e.g. its own stack, which it is still using
e.g. its struct context, which it may need to call swtch()
xv6 has two ways to get rid of processes: exit() and kill()
ordinary case: process voluntarily quits with exit() system call
some freeing in exit(), some in parent’s wait()
exit() in proc.c:
close open files
change parent of children to PID 1 (init)
wake up wait()ing parent
p->state = ZOMBIE
dying but not yet dead
won’t run again
won’t (yet) be re-allocated by fork(), eithe·r
(note stack and proc[] entry are still allocated…)
swtch() to scheduler
wait() in proc.c (parent, or init, will eventually call):
sleep()s waiting for any child exit()
scans proc[] table for children with p->state==ZOMBIE
calls freeproc()
(p->lock held…)
trapframe, pagetable, …, p->state=UNUSED
thus: wait() is not just for app convenience, but for O/S as well
every process must be wait()ed for
thus the re-parenting of children of an exiting process
some complexity due to
child exits concurrently with its own parent
parent-then-child locking order to avoid deadlock
what about kill(pid)?
problem: may not be safe to forcibly terminate a process it might be executing in the kernel using its kernel stack, page table, proc[] entry, trapframe it might hold locks e.g. in the middle of fork()ing a new process and must finish to restore invariants so: kill() can’t directly destroy the target! solution: kill() sets p->killed flag, nothing else the target process itself checks for p->killed and calls exit() itself look for “if(p->killed) exit(-1);” in usertrap() no locks are held at that point so it’s safe to exit()
what if kill() target is sleep()ing?
in that case it doesn’t hold locks, and isn’t executing! is it OK for kill() destroy the target right away? might be OK: waiting for console input might not be OK: waiting for disk midway through file creation
xv6 solution to kill() of sleep()ing process
see kill() in proc.c
changes SLEEPING to RUNNABLE – like wakeup()
so sleep() will return, probably before condition is true
some sleep loops check for p->killed
e.g. piperead(), consoleread()
otherwise read could hang indefinitely for a killed process
some sleep loops don’t check p->killed
e.g. virtio_disk.c
OK not to check p->killed since disk reads are pretty quick
so a kill()ed process may continue for a while
but usertrap() will exit() after the system call finishes
xv6 spec for kill
if target is in user space will die next time it makes a system call or takes a timer interrupt if target is in the kernel target will never execute another user instruction but may spend quite a while yet in the kernel
Summary
sleep/wakeup let threads wait for specific events concurrency means we have to worry about lost wakeups termination is a pain in threading systems
Lab: locks
Memory allocator (moderate)
优化xv6的内存分配器,减少锁争用。当前的实现使用一个全局的自由列表和单一的锁保护,导致多核系统中多个进程并发执行时锁争用严重。你需要将单一自由列表改为每个CPU都有自己的自由列表,每个自由列表有自己的锁。这样,多个CPU可以并行进行内存分配和释放,从而减少锁争用。
任务分解:
- 创建每个CPU的自由列表:
- 每个CPU有自己独立的自由内存块列表,并且每个列表有自己的锁。
- 使用
NCPU(在param.h中定义)确定CPU的数量。 - 为每个CPU创建一个对应的锁,用于保护其自由列表。
- 修改
freerange函数:freerange应该根据当前CPU,将空闲内存块分配到当前CPU的自由列表中。你可以使用cpuid来获取当前CPU编号,但要确保调用它时中断已关闭。- 使用
push_off()和pop_off()来关闭和开启中断,保证调用cpuid时的安全性。
- 实现内存分配和释放:
- 修改
kalloc和kfree,使它们只操作当前CPU的自由列表。通过使用当前CPU的锁来保护并发访问。 - 当某个CPU的自由列表为空时,需要从其他CPU的自由列表中“偷取”内存块。
- 修改
- 实现跨CPU的内存“偷取”:
- 如果当前CPU的自由列表为空,查找其他CPU的自由列表,尝试从中“偷取”部分内存。
- “偷取”过程可能引入锁争用,但由于偷取发生较少,可以将争用控制在较低范围。
- 锁的命名:
- 根据要求,所有涉及的锁必须以“kmem”开头。你可以使用
initlock函数来初始化锁,并使用合适的名称(如kmem_cpu0、kmem_cpu1等)。
- 根据要求,所有涉及的锁必须以“kmem”开头。你可以使用
- 测试:
- 运行
kalloctest,观察kmem锁的争用情况,争用次数应明显减少。 - 运行
usertests sbrkmuch测试内存分配器,确保所有内存分配和释放功能正常。
- 运行
实现步骤:
1、定义每个CPU的自由列表: 在kmem结构中,添加一个数组保存每个CPU的自由列表和对应的锁
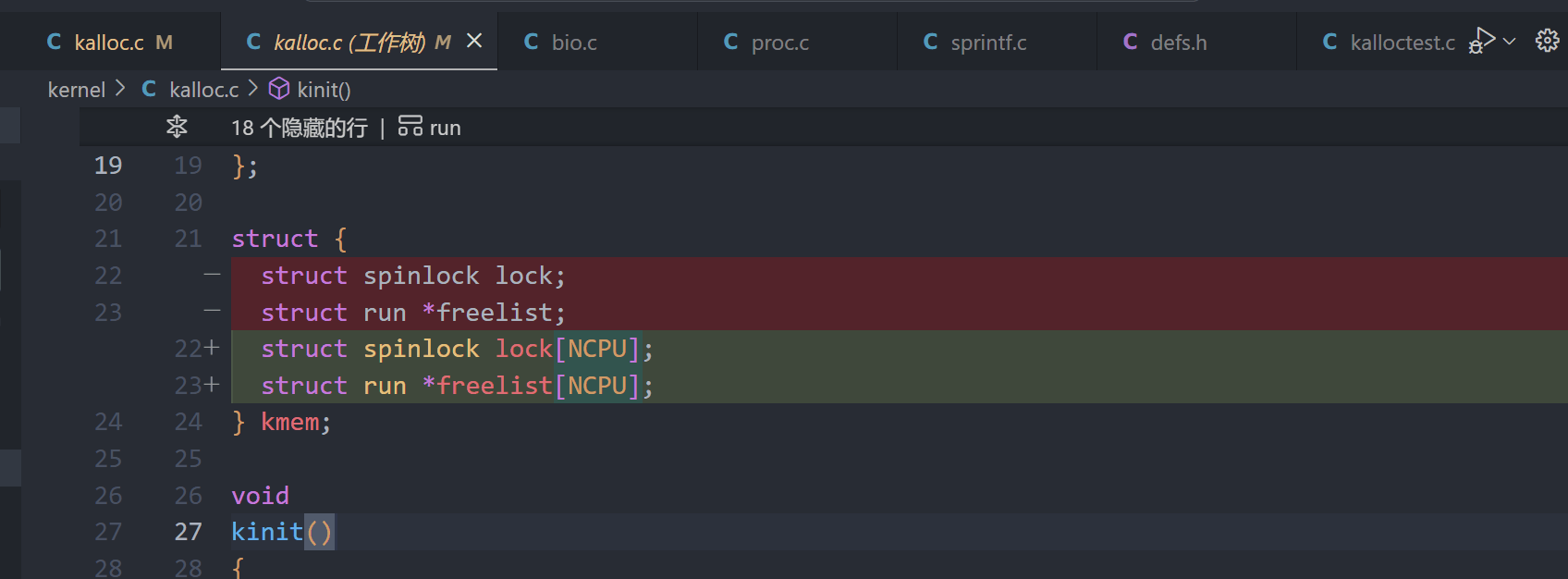
struct {
struct spinlock lock[NCPU];
struct run *freelist[NCPU];
} kmem;
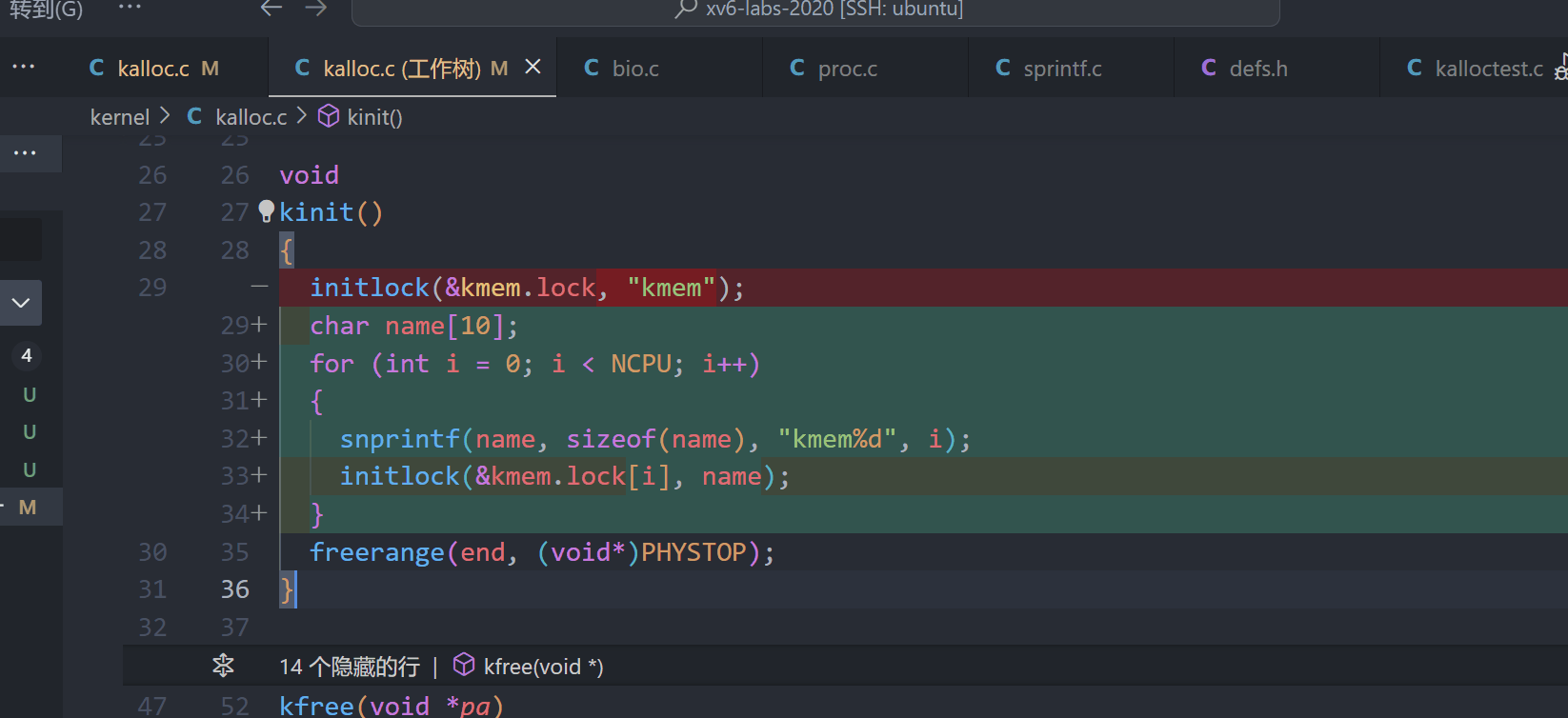
2、初始化每个CPU的锁和自由列表: 在freerange函数中,为当前CPU的自由列表分配内存,并用initlock为每个CPU的锁进行初始化:
3、修改kalloc函数: 使用当前CPU的自由列表分配内存,并在列表为空时从其他CPU的自由列表中“偷取”内存:
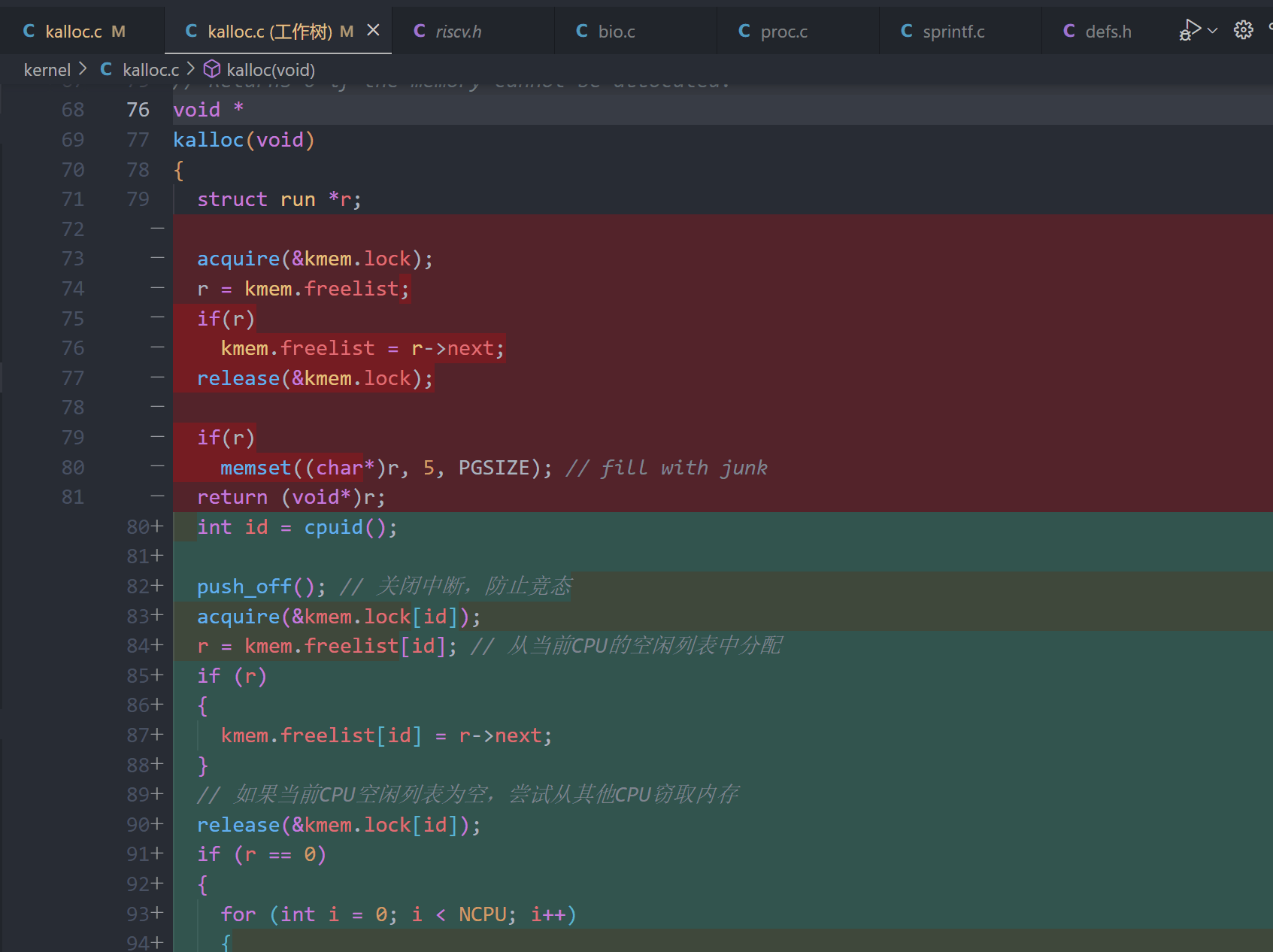
void *
kalloc(void)
{
struct run *r;
int id = cpuid();
push_off(); // 关闭中断,防止竞态
acquire(&kmem.lock[id]);
r = kmem.freelist[id]; // 从当前CPU的空闲列表中分配
if (r)
{
kmem.freelist[id] = r->next;
}
// 如果当前CPU空闲列表为空,尝试从其他CPU窃取内存
release(&kmem.lock[id]);
if (r == 0)
{
for (int i = 0; i < NCPU; i++)
{
if (i != id)
{
acquire(&kmem.lock[i]);
r = kmem.freelist[i];
if (r)
{
kmem.freelist[i] = r->next;
release(&kmem.lock[i]);
break;
}
release(&kmem.lock[i]);
}
}
}
pop_off();
if (r)
memset((char *)r, 5, PGSIZE); // fill with junk
return (void *)r;
}
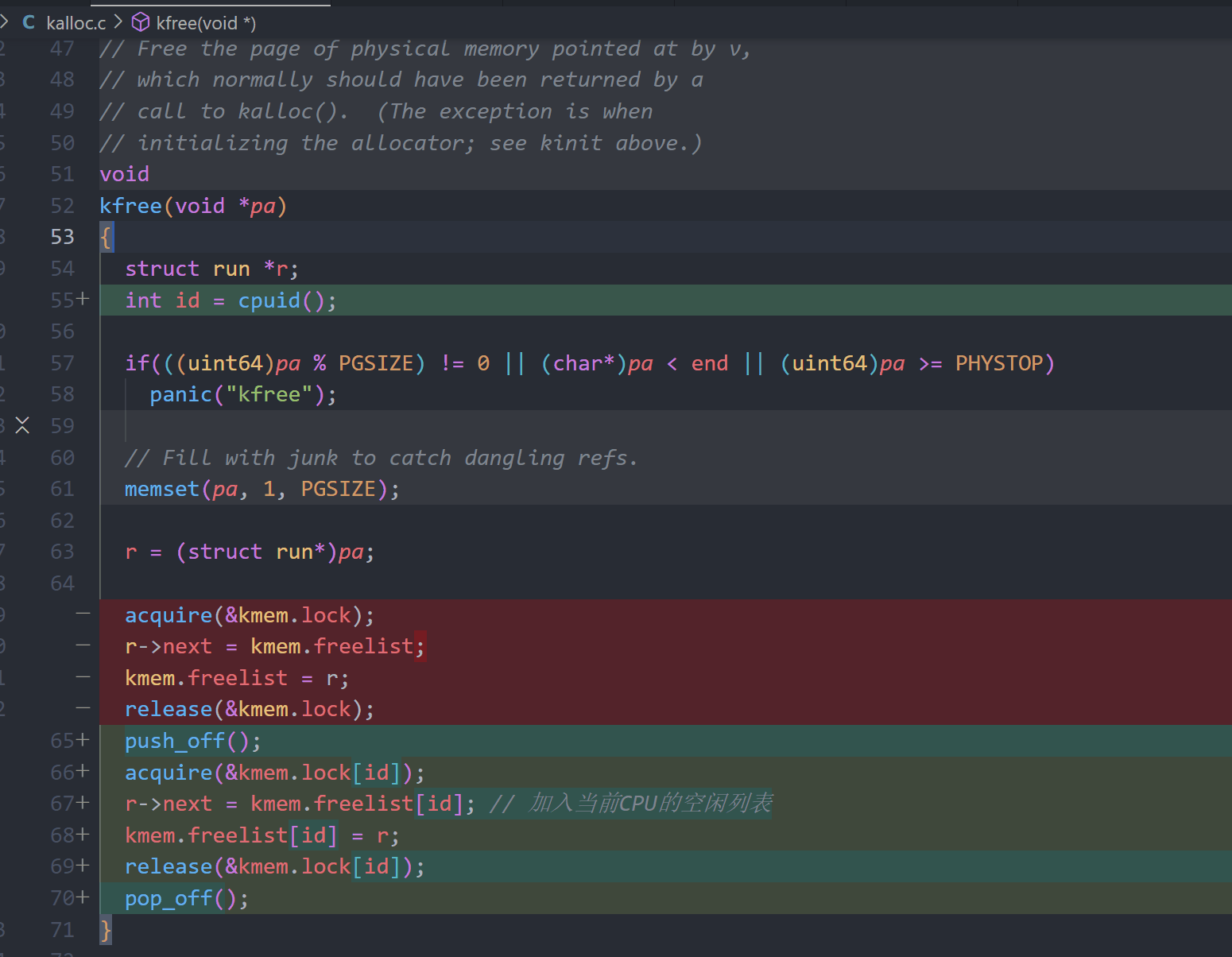
4、修改kfree函数: 将释放的内存块放入当前CPU的自由列表,并使用当前CPU的锁保护:
5、(之前第3步中已经包括下面的代码实现)实现“偷取”机制: 在kalloc函数中,当当前CPU的自由列表为空时,遍历其他CPU的自由列表并“偷取”内存块,具体逻辑可能如下:
for (int i = 0; i < NCPU; i++)
{
if (i != id)
{
acquire(&kmem.lock[i]);
r = kmem.freelist[i];
if (r)
{
kmem.freelist[i] = r->next;
release(&kmem.lock[i]);
break;
}
release(&kmem.lock[i]);
}
}
最终检查:
- 运行
kalloctest和usertests sbrkmuch,确保所有内存分配、释放和并发处理正常,同时锁争用显著减少。
Buffer cache (hard)
修改 xv6 的块缓存(block cache)机制,减少多个进程同时访问缓存时对锁 bcache.lock 的争用。你需要特别优化 bget 和 brelse 函数,确保并发读取和释放不同的缓存块时不会冲突。最终的目标是让运行 bcachetest 时,所有与块缓存相关的锁的获取次数接近零(理想情况下总和小于500)。此外,你需要通过 usertests 测试,并且确保实现中的锁名都以“bcache”开头。
实现步骤详细说明:
- 理解现有锁争用:
bcache.lock保护了缓存块列表、缓存块的引用计数b->refcnt以及缓存块的标识b->dev和b->blockno。多个进程同时访问时可能发生锁争用。
- 使用哈希表替代全局缓存锁:
- 使用一个哈希表来存储缓存块,并为每个哈希桶设置单独的锁。通过哈希分桶机制,你可以减少并发访问不同缓存块时对同一个锁的争用。
- 可以选择使用一个质数(例如13)作为哈希桶的数量,以减少哈希冲突的概率。
- 修改
bget和brelse:bget:这是获取缓存块的函数。你需要修改它,使得在查找和获取缓存块时,只对相应的哈希桶进行加锁,而不是全局加锁。同时,确保如果缓存中没有对应的块,需要选择一个替换块时,替换逻辑是原子的,并且防止哈希冲突导致的死锁。brelse:这是释放缓存块的函数。你可以通过使用时间戳(如ticks)来记录缓存块的最后使用时间,从而避免在释放块时必须获取全局bcache.lock。当brelse被调用时,只需要更新时间戳,而不需要加锁。
- 替换缓存块的管理机制:
- 取消全局缓存块链表(如
bcache.head等),而是通过时间戳记录缓存块的最后使用时间。这样,你可以在bget中根据时间戳选择最近未使用的缓存块,而不需要遍历全局列表。
- 取消全局缓存块链表(如
- 防止死锁:
- 在缓存替换和哈希桶移动时,可能需要持有多个锁(如全局
bcache.lock和哈希桶锁)。你需要小心避免在锁的顺序上出现死锁的情况,特别是在缓存块从一个哈希桶移动到另一个桶时。
- 在缓存替换和哈希桶移动时,可能需要持有多个锁(如全局
- 逐步调试:
- 你可以在实现哈希桶锁后,先保留
bget开始和结束时的全局锁bcache.lock,以确保没有竞争条件。一旦验证代码没有竞态条件后,再移除全局锁,处理并发问题。 - 可以运行
make CPUS=1 qemu进行单核测试,确保初步实现正确后,再扩展到多核环境。
- 你可以在实现哈希桶锁后,先保留
usertests不通过
// Buffer cache.
//
// The buffer cache is a linked list of buf structures holding
// cached copies of disk block contents. Caching disk blocks
// in memory reduces the number of disk reads and also provides
// a synchronization point for disk blocks used by multiple processes.
//
// Interface:
// * To get a buffer for a particular disk block, call bread.
// * After changing buffer data, call bwrite to write it to disk.
// * When done with the buffer, call brelse.
// * Do not use the buffer after calling brelse.
// * Only one process at a time can use a buffer,
// so do not keep them longer than necessary.
#include "types.h"
#include "param.h"
#include "spinlock.h"
#include "sleeplock.h"
#include "riscv.h"
#include "defs.h"
#include "fs.h"
#include "buf.h"
#define NBUCKETS 23 // 哈希桶数量,使用质数以减少冲突
struct
{
struct spinlock lock;
struct buf buf[NBUF]; // 实际的缓存块
struct
{
struct buf *head; // 每个桶的缓存块链表
struct spinlock lock; // 每个桶的锁
} buckets[NBUCKETS];
} bcache;
// 计算块号和设备号的哈希值
static uint
hash(uint dev, uint blockno)
{
return (dev ^ blockno) % NBUCKETS;
}
void binit(void)
{
struct buf *b;
initlock(&bcache.lock, "bcache");
// 初始化每个桶的锁
for (int i = 0; i < NBUCKETS; i++)
{
initlock(&bcache.buckets[i].lock, "bcache.bucket");
bcache.buckets[i].head = 0;
}
// 初始化缓存块
for (b = bcache.buf; b < bcache.buf + NBUF; b++)
{
initsleeplock(&b->lock, "buffer");
b->refcnt = 0;
}
}
// 修改 bget 函数进行哈希表查找
// 为了使用哈希表,bget 函数需要进行以下修改:
// 计算块号的哈希值,确定所在桶。
// 获取桶的锁,并在桶中查找块。
// 如果未找到块,则选择一个未使用或最近最少使用的块进行替换。
static struct buf *
bget(uint dev, uint blockno)
{
struct buf *b;
uint h = hash(dev, blockno);
acquire(&bcache.buckets[h].lock);
// 在桶中查找块
for (b = bcache.buckets[h].head; b; b = b->next)
{
if (b->dev == dev && b->blockno == blockno)
{
b->refcnt++;
release(&bcache.buckets[h].lock);
acquiresleep(&b->lock);
return b;
}
}
// 如果未找到块,尝试找到一个未使用的块或替换最近最少使用的块
struct buf *lru = 0;
for (b = bcache.buf; b < bcache.buf + NBUF; b++)
{
if (b->refcnt == 0 && (lru == 0 || b->lastuse < lru->lastuse))
lru = b;
}
if (lru == 0)
panic("bget: no buffers");
release(&bcache.buckets[h].lock);
// 从旧桶中移除块
h = hash(lru->dev, lru->blockno);
acquire(&bcache.buckets[h].lock);
struct buf **prev = &bcache.buckets[h].head;
for (b = bcache.buckets[h].head; b; prev = &b->next, b = b->next)
{
if (b == lru)
{
*prev = b->next;
break;
}
}
// 将新块插入适当的桶
lru->dev = dev;
lru->blockno = blockno;
lru->valid = 0;
lru->refcnt = 1;
lru->lastuse = ticks;
release(&bcache.buckets[h].lock);
h = hash(dev, blockno);
acquire(&bcache.buckets[h].lock);
lru->next = bcache.buckets[h].head;
bcache.buckets[h].head = lru;
release(&bcache.buckets[h].lock);
acquiresleep(&lru->lock);
return lru;
}
// Return a locked buf with the contents of the indicated block.
struct buf *
bread(uint dev, uint blockno)
{
struct buf *b;
b = bget(dev, blockno);
if (!b->valid)
{
virtio_disk_rw(b, 0);
b->valid = 1;
}
return b;
}
// Write b's contents to disk. Must be locked.
void bwrite(struct buf *b)
{
if (!holdingsleep(&b->lock))
panic("bwrite");
virtio_disk_rw(b, 1);
}
// Release a locked buffer.
// Move to the head of the most-recently-used list.
void brelse(struct buf *b)
{
if (!holdingsleep(&b->lock))
panic("brelse");
releasesleep(&b->lock);
uint h = hash(b->dev, b->blockno);
acquire(&bcache.buckets[h].lock);
b->refcnt--;
if (b->refcnt == 0)
{
// 块不再被使用,更新时间戳
b->lastuse = ticks;
}
release(&bcache.buckets[h].lock);
}
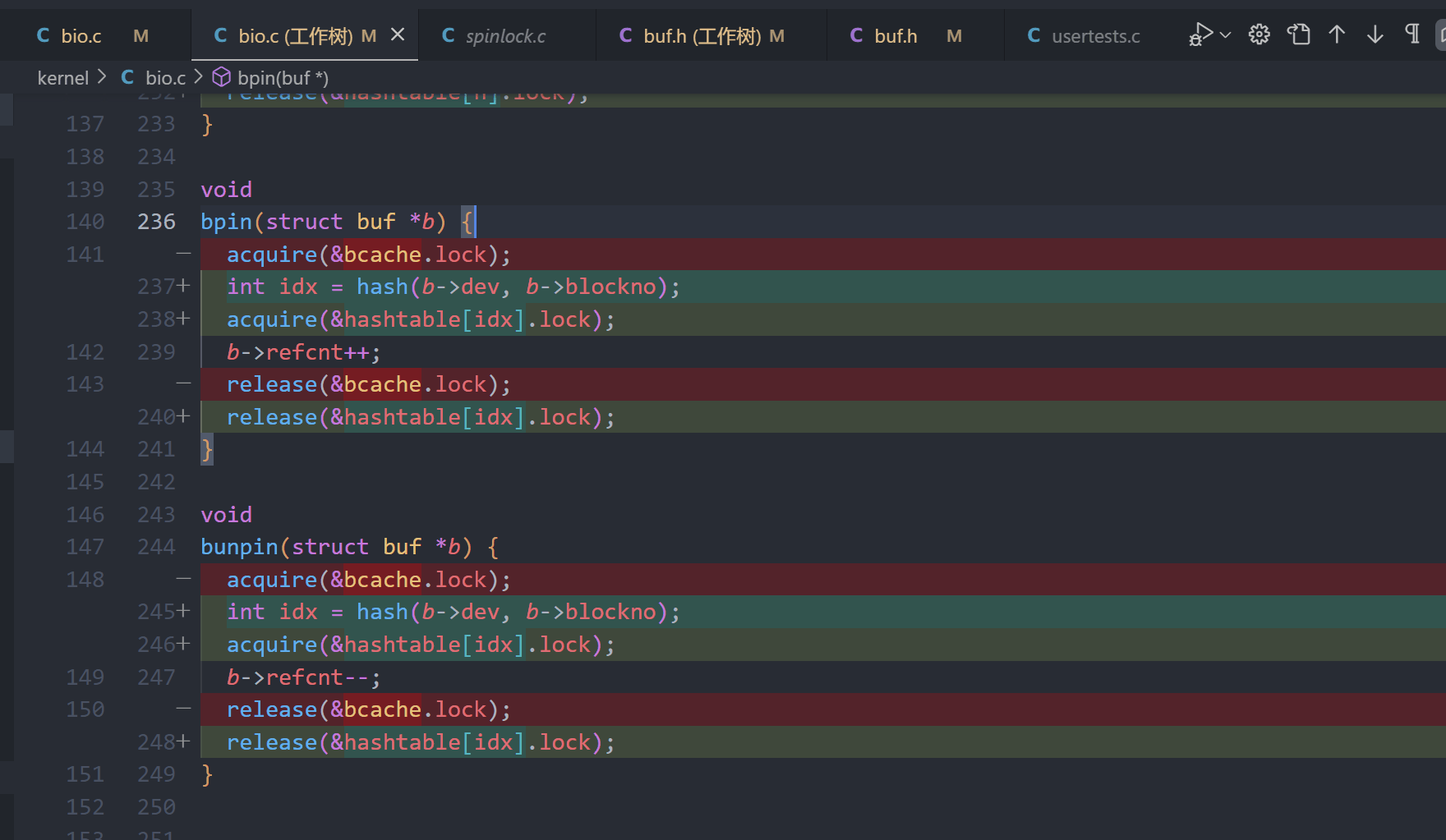
void bpin(struct buf *b)
{
uint h = hash(b->dev, b->blockno);
acquire(&bcache.buckets[h].lock);
b->refcnt++;
release(&bcache.buckets[h].lock);
}
void bunpin(struct buf *b)
{
uint h = hash(b->dev, b->blockno);
acquire(&bcache.buckets[h].lock);
b->refcnt--;
release(&bcache.buckets[h].lock);
}
// Buffer cache.
//
// The buffer cache is a linked list of buf structures holding
// cached copies of disk block contents. Caching disk blocks
// in memory reduces the number of disk reads and also provides
// a synchronization point for disk blocks used by multiple processes.
//
// Interface:
// * To get a buffer for a particular disk block, call bread.
// * After changing buffer data, call bwrite to write it to disk.
// * When done with the buffer, call brelse.
// * Do not use the buffer after calling brelse.
// * Only one process at a time can use a buffer,
// so do not keep them longer than necessary.
#include "types.h"
#include "param.h"
#include "spinlock.h"
#include "sleeplock.h"
#include "riscv.h"
#include "defs.h"
#include "fs.h"
#include "buf.h"
#define NBUCKET 13
#undef NBUF
#define NBUF (NBUCKET * 3)
struct {
struct spinlock lock;
struct buf buf[NBUF];
} bcache;
struct bucket {
struct spinlock lock;
struct buf head;
}hashtable[NBUCKET];
int
hash(uint dev, uint blockno)
{
return blockno % NBUCKET;
}
void
binit(void)
{
struct buf *b;
initlock(&bcache.lock, "bcache");
for(b = bcache.buf; b < bcache.buf+NBUF; b++){
initsleeplock(&b->lock, "buffer");
}
b = bcache.buf;
for (int i = 0; i < NBUCKET; i++) {
initlock(&hashtable[i].lock, "bcache_bucket");
for (int j = 0; j < NBUF / NBUCKET; j++) {
b->blockno = i;
b->next = hashtable[i].head.next;
hashtable[i].head.next = b;
b++;
}
}
}
// Look through buffer cache for block on device dev.
// If not found, allocate a buffer.
// In either case, return locked buffer.
static struct buf*
bget(uint dev, uint blockno)
{
// printf("dev: %d blockno: %d Status: ", dev, blockno);
struct buf *b;
int idx = hash(dev, blockno);
struct bucket* bucket = hashtable + idx;
acquire(&bucket->lock);
// Is the block already cached?
for(b = bucket->head.next; b != 0; b = b->next){
if(b->dev == dev && b->blockno == blockno){
b->refcnt++;
release(&bucket->lock);
acquiresleep(&b->lock);
// printf("Cached %p\n", b);
return b;
}
}
// Not cached.
// First try to find in current bucket.
int min_time = 0x8fffffff;
struct buf* replace_buf = 0;
for(b = bucket->head.next; b != 0; b = b->next){
if(b->refcnt == 0 && b->timestamp < min_time) {
replace_buf = b;
min_time = b->timestamp;
}
}
if(replace_buf) {
// printf("Local %d %p\n", idx, replace_buf);
goto find;
}
// Try to find in other bucket.
acquire(&bcache.lock);
refind:
for(b = bcache.buf; b < bcache.buf + NBUF; b++) {
if(b->refcnt == 0 && b->timestamp < min_time) {
replace_buf = b;
min_time = b->timestamp;
}
}
if (replace_buf) {
// remove from old bucket
int ridx = hash(replace_buf->dev, replace_buf->blockno);
acquire(&hashtable[ridx].lock);
if(replace_buf->refcnt != 0) // be used in another bucket's local find between finded and acquire
{
release(&hashtable[ridx].lock);
goto refind;
}
struct buf *pre = &hashtable[ridx].head;
struct buf *p = hashtable[ridx].head.next;
while (p != replace_buf) {
pre = pre->next;
p = p->next;
}
pre->next = p->next;
release(&hashtable[ridx].lock);
// add to current bucket
replace_buf->next = hashtable[idx].head.next;
hashtable[idx].head.next = replace_buf;
release(&bcache.lock);
// printf("Global %d -> %d %p\n", ridx, idx, replace_buf);
goto find;
}
else {
panic("bget: no buffers");
}
find:
replace_buf->dev = dev;
replace_buf->blockno = blockno;
replace_buf->valid = 0;
replace_buf->refcnt = 1;
release(&bucket->lock);
acquiresleep(&replace_buf->lock);
return replace_buf;
}
// Return a locked buf with the contents of the indicated block.
struct buf*
bread(uint dev, uint blockno)
{
struct buf *b;
b = bget(dev, blockno);
if(!b->valid) {
virtio_disk_rw(b, 0);
b->valid = 1;
}
return b;
}
// Write b's contents to disk. Must be locked.
void
bwrite(struct buf *b)
{
if(!holdingsleep(&b->lock))
panic("bwrite");
virtio_disk_rw(b, 1);
}
// Release a locked buffer.
// Move to the head of the most-recently-used list.
void
brelse(struct buf *b)
{
if(!holdingsleep(&b->lock))
panic("brelse");
releasesleep(&b->lock);
int idx = hash(b->dev, b->blockno);
acquire(&hashtable[idx].lock);
b->refcnt--;
if (b->refcnt == 0) {
// no one is waiting for it.
b->timestamp = ticks;
}
release(&hashtable[idx].lock);
}
void
bpin(struct buf *b) {
int idx = hash(b->dev, b->blockno);
acquire(&hashtable[idx].lock);
b->refcnt++;
release(&hashtable[idx].lock);
}
void
bunpin(struct buf *b) {
int idx = hash(b->dev, b->blockno);
acquire(&hashtable[idx].lock);
b->refcnt--;
release(&hashtable[idx].lock);
}
实现步骤
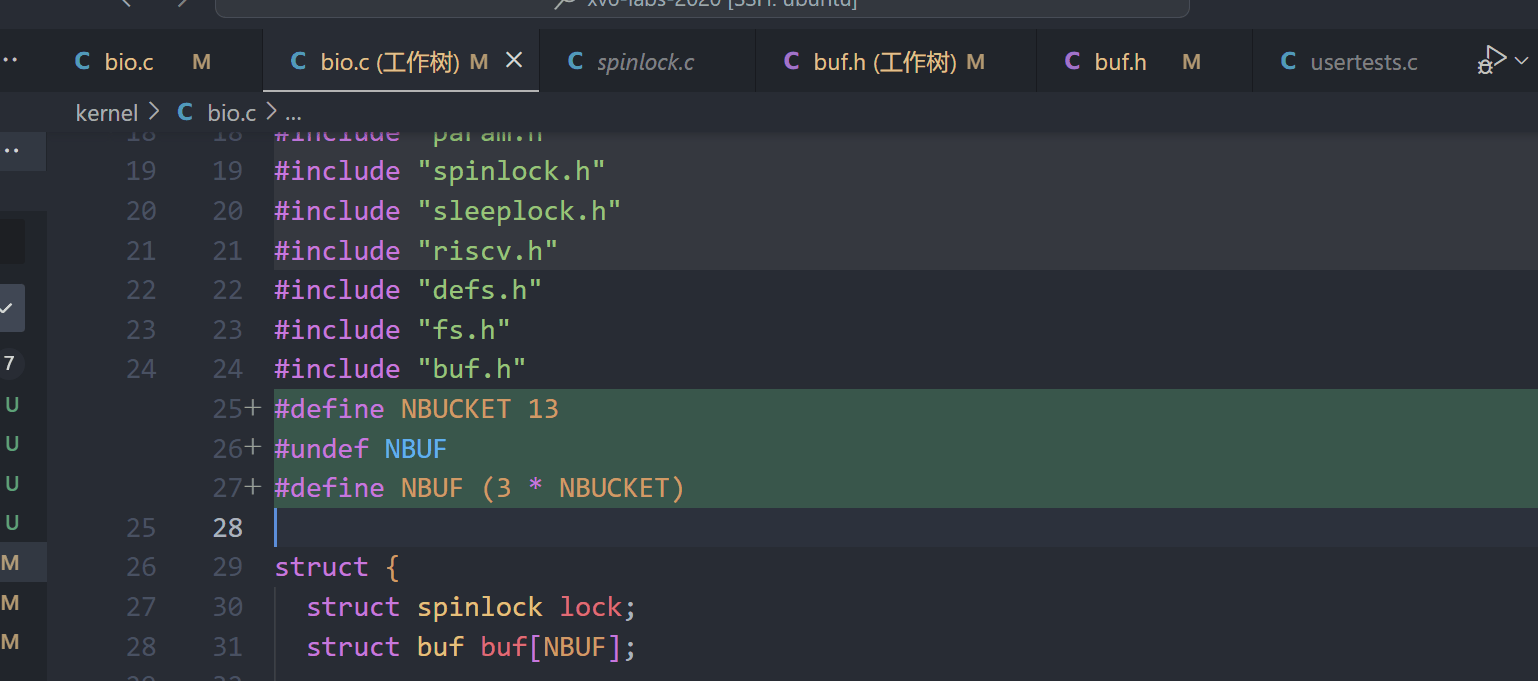
1、定义桶大小,以及全局的buffer大小
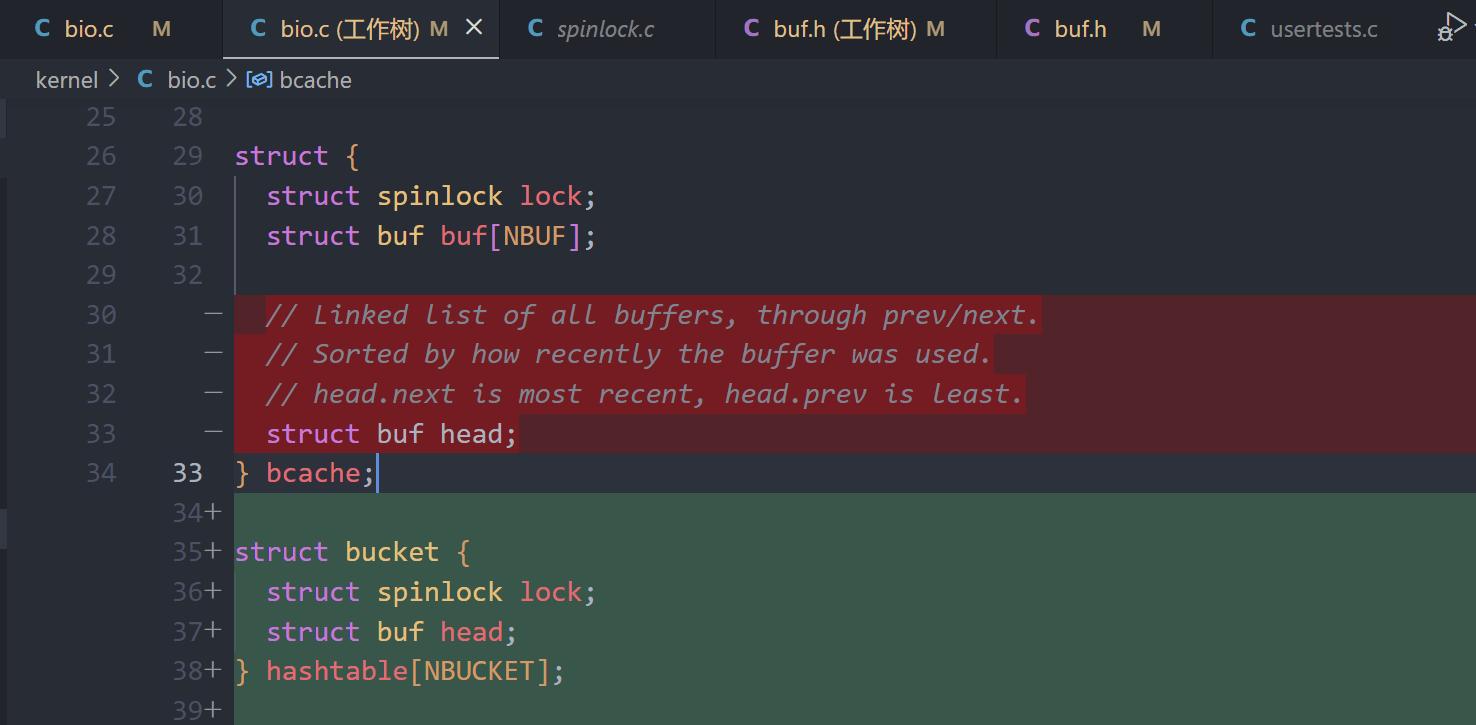
2、添加bucket结构体
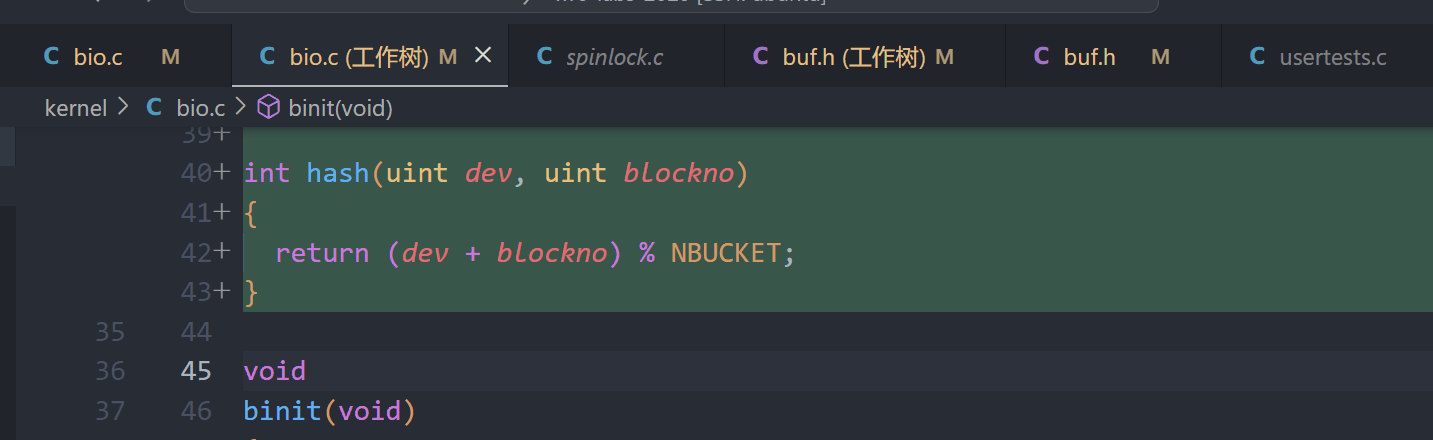
3、实现哈希函数
4、初始化实现全局buffer初始化,以及每个桶内的buffer初始化
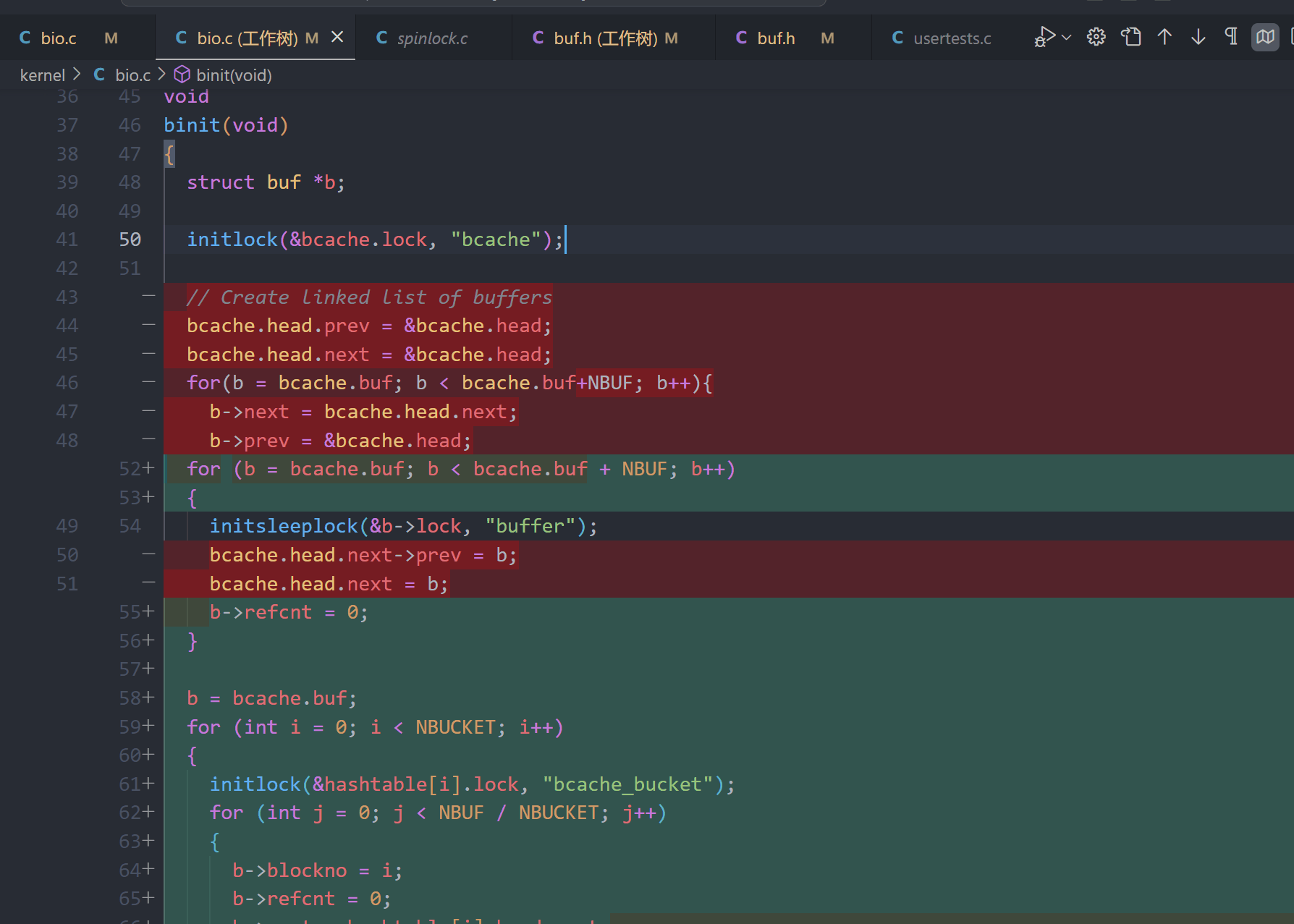
void
binit(void)
{
struct buf *b;
initlock(&bcache.lock, "bcache");
for (b = bcache.buf; b < bcache.buf + NBUF; b++)
{
initsleeplock(&b->lock, "buffer");
b->refcnt = 0;
}
b = bcache.buf;
for (int i = 0; i < NBUCKET; i++)
{
initlock(&hashtable[i].lock, "bcache_bucket");
for (int j = 0; j < NBUF / NBUCKET; j++)
{
b->blockno = i;
b->refcnt = 0;
b->next = hashtable[i].head.next;
hashtable[i].head.next = b;
b++;
}
}
}
5、重点, 重构bget(),桶内寻找是否已经缓存->桶内寻找空白缓存 ->寻找全局空白缓存
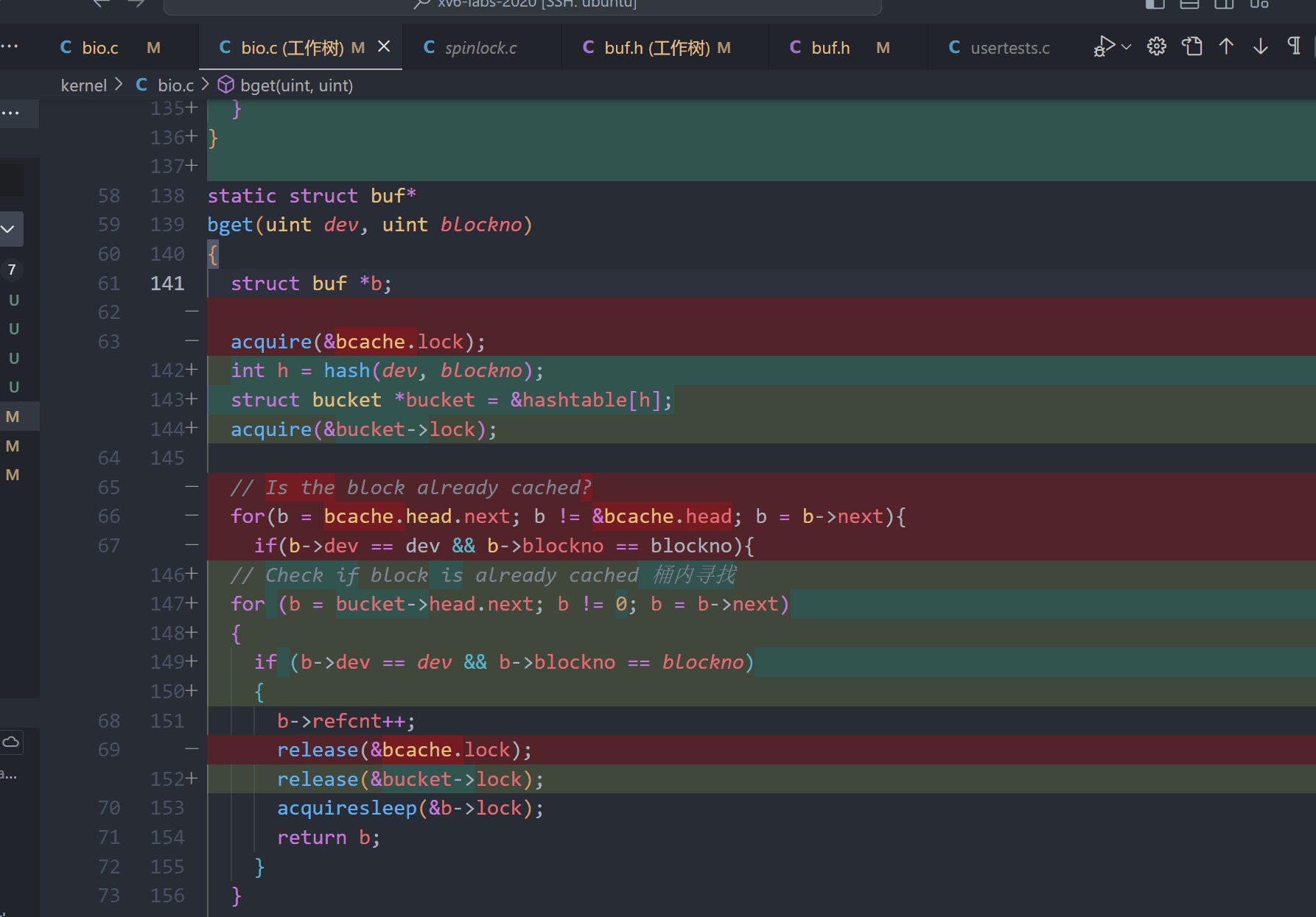
static struct buf *
find_replacement_in_bucket(struct bucket *bucket, uint *min_time)
{
struct buf *replace_buf = 0;
struct buf *b;
for (b = bucket->head.next; b != 0; b = b->next)
{
if (b->refcnt == 0 && (*min_time == 0 || b->timestamp < *min_time))
{
replace_buf = b;
*min_time = b->timestamp;
}
}
return replace_buf;
}
static struct buf *
find_replacement_in_global(struct buf *replace_buf, uint *min_time)
{
struct buf *b;
for (b = bcache.buf; b < bcache.buf + NBUF; b++)
{
if (b->refcnt == 0 && (*min_time == 0 || b->timestamp < *min_time))
{
replace_buf = b;
*min_time = b->timestamp;
}
}
return replace_buf;
}
static void
move_buf_to_bucket(struct buf *replace_buf, int idx)
{
int ridx = hash(replace_buf->dev, replace_buf->blockno);
acquire(&hashtable[ridx].lock);
if (replace_buf->refcnt == 0)
{
struct buf *pre = &hashtable[ridx].head;
struct buf *p = hashtable[ridx].head.next;
while (p != replace_buf)
{
pre = pre->next;
p = p->next;
}
pre->next = p->next;
release(&hashtable[ridx].lock);
// Add to current bucket
replace_buf->next = hashtable[idx].head.next;
hashtable[idx].head.next = replace_buf;
}
else
{
release(&hashtable[ridx].lock);
}
}
static struct buf*
bget(uint dev, uint blockno)
{
struct buf *b;
int h = hash(dev, blockno);
struct bucket *bucket = &hashtable[h];
acquire(&bucket->lock);
// Check if block is already cached 桶内寻找
for (b = bucket->head.next; b != 0; b = b->next)
{
if (b->dev == dev && b->blockno == blockno)
{
b->refcnt++;
release(&bucket->lock);
acquiresleep(&b->lock);
return b;
}
}
// Not cached, find replacement buffer 桶内的空白buf
uint min_time = 0;
struct buf *replace_buf;
replace_buf = find_replacement_in_bucket(bucket, &min_time);
if (!replace_buf)
{
acquire(&bcache.lock);
// 寻找桶外的空白buf
replace_buf = find_replacement_in_global(replace_buf, &min_time);
if (replace_buf)
{
move_buf_to_bucket(replace_buf, h);
}
else
{
release(&bcache.lock);
panic("bget: no buffers");
}
release(&bcache.lock);
}
// Initialize and return the replacement buffer
replace_buf->dev = dev;
replace_buf->blockno = blockno;
replace_buf->valid = 0;
replace_buf->refcnt = 1;
release(&bucket->lock);
acquiresleep(&replace_buf->lock);
return replace_buf;
}
6、锁的释放,更新引用计数,当refcnt == 0时更新时间戳
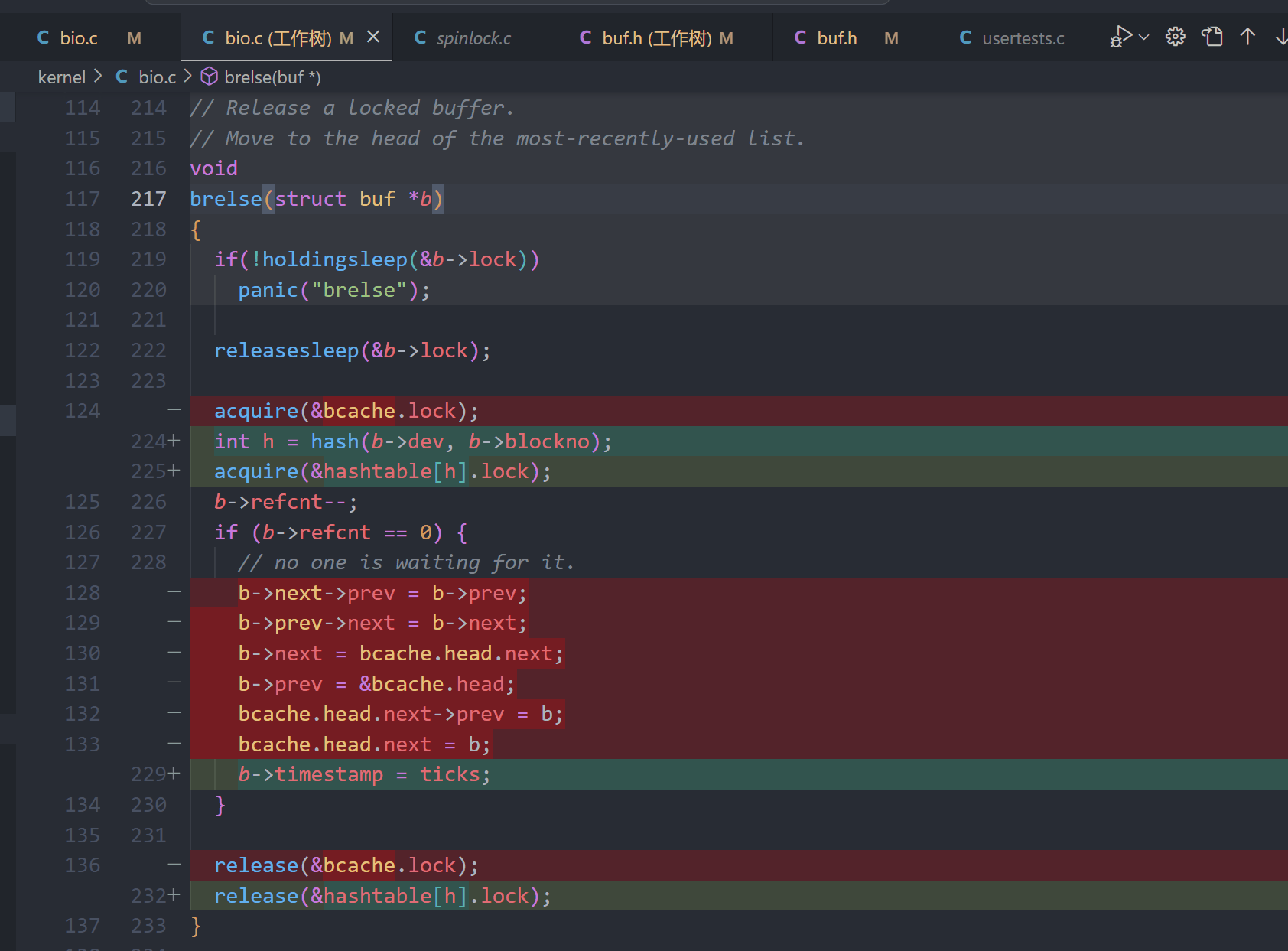
7、更新 bpin() 和 bunpin(), 只需要持有对应桶的锁即可