MIT6.S081(4)-Virtual Memory
Plan:
-
Address spaces
-
Paging hardware
-
xv6 VM code
Virtual memory overview
Today’s problem:
[user/kernel diagram] [memory view: diagram with user processes and kernel in memory]
Suppose the shell has a bug:
- sometimes it writes to a random memory address
how can we keep it from wrecking the kernel? and from wrecking other processes?
we want isolated address spaces each process has its own memory it can read and write its own memory it cannot read or write anything else
challenge:
How to multiplex several memories over one physical memory?
while maintaining isolation between memories
- xv6 uses RISC-V’s paging hardware to implement AS(Address Space)’s ask questions! this material is important topic of next lab (and shows up in several other labs)
paging provides a level of indirection for addressing
CPU -> MMU -> RAM
VA PA
s/w can only ld/st to virtual addresses, not physical
kernel tells MMU how to map each virtual address to a physical address
MMU(Memory Management Unit) essentially has a table, indexed by va, yielding pa
called a “page table”
one page table per address space
MMU can restrict what virtual addresses user code can use
By programming the MMU, the kernel has complete control over va->pa mapping
Allows for many interesting OS features/tricks
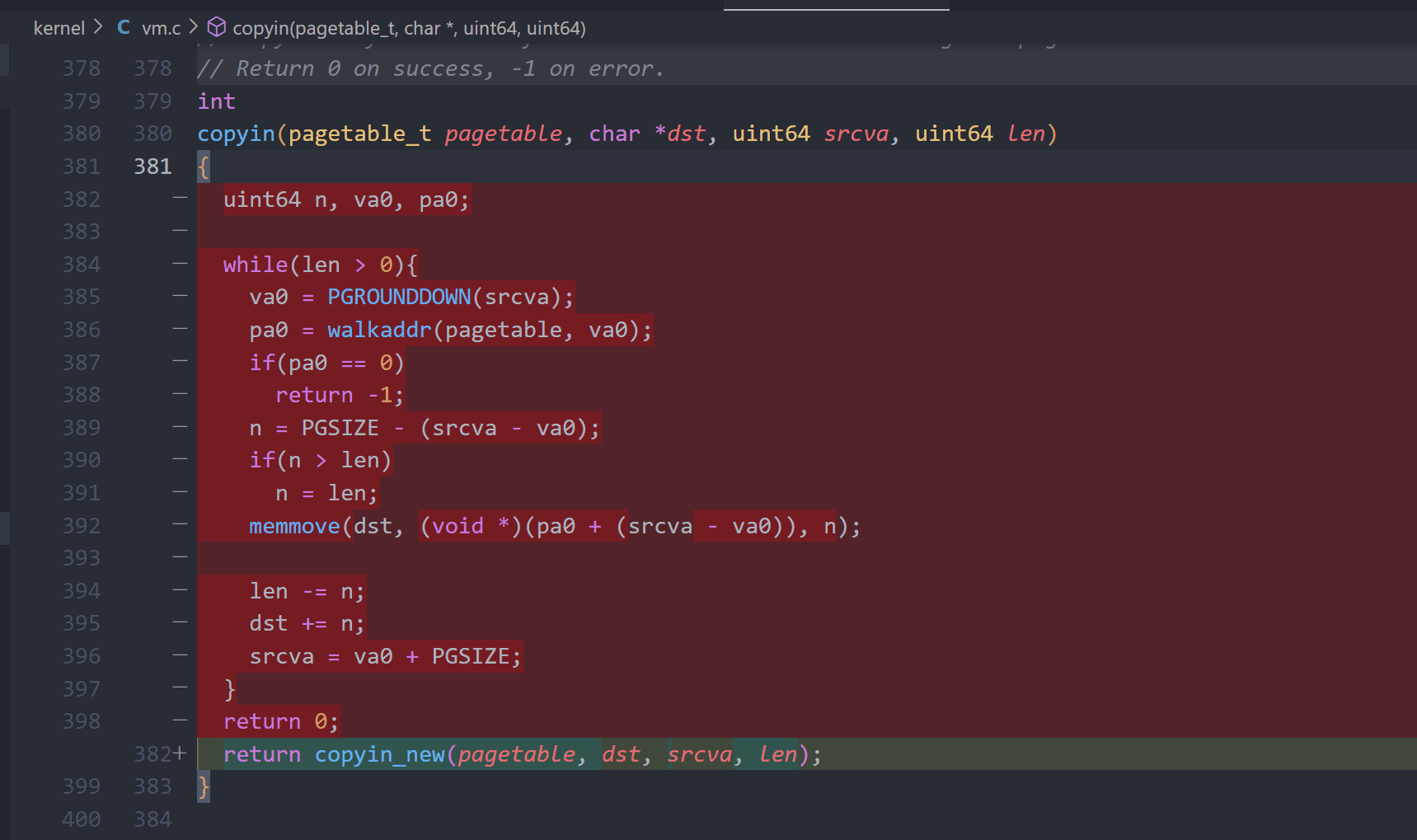
- RISC-V maps 4-KB “pages” and aligned – start on 4 KB boundaries $4 KB = 12 bits$ the RISC-V used in xv6 has 64-bit for addresses thus page table index is top 64-12 = 52 bits of VA except that the top 25 of the top 52 are unused no RISC-V has that much memory now can grow in future so, index is 27 bits.
MMU translation
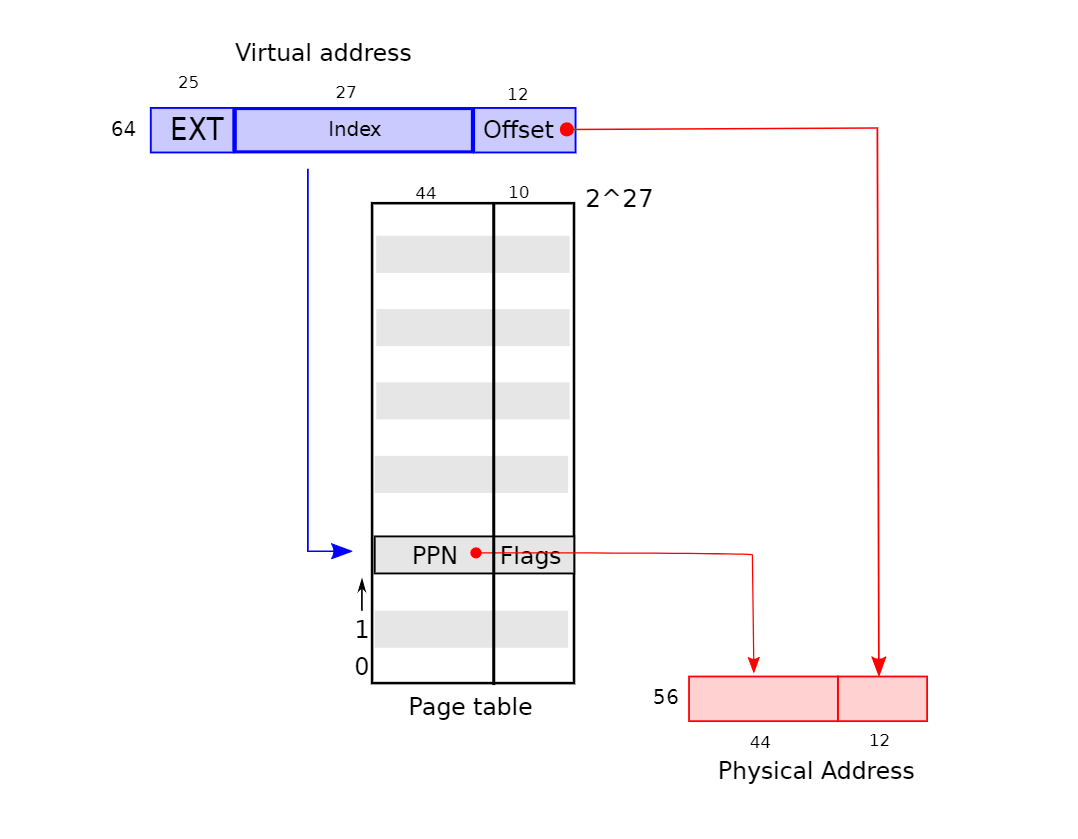
- see Figure 3.1 of book use index bits of VA to find a page table entry (PTE) construct physical address using PPN from PTE + offset of VA
What is in PTE? each PTE is 64 bits, but only 54 are used top 44 bits of PTE are top bits of physical address “physical page number” low 10 bits of PTE flags Present, Writeable, &c note: size virtual addresses != size physical addresses
Where is the page table stored?
in RAM – MMU loads (and stores) PTEs o/s can read/write PTEs read/write memory location corresponding to PTEs
Would it be reasonable for page table to just be an array of PTEs?
how big is it? 2^27 is roughly 134 million 64 bits per entry 134*8 MB for a full page table wasting roughly 1GB per page table one page table per address space one address space per application would waste lots of memory for small programs! you only need mappings for a few hundred pages so the rest of the million entries would be there but not needed
RISC-V 64 uses a “three-level page table” to save space
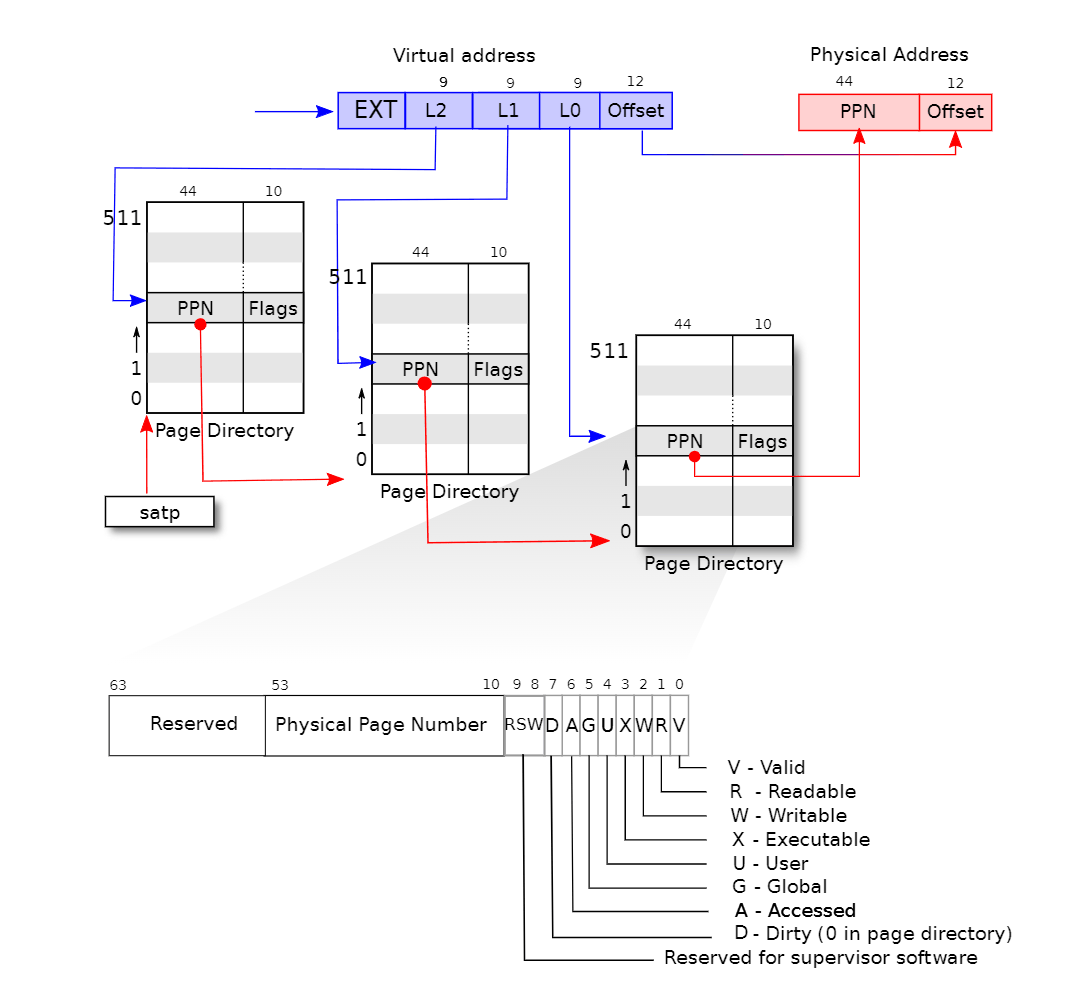
see figure 3.2 from book page directory page (PD) PD has 512 PTEs PTEs point to another PD or is a leaf so 512512512 PTEs in total PD entries can be invalid those PTE pages need not exist so a page table for a small address space can be small
how does the mmu know where the page table is located in RAM? satp holds phys address of top PD pages can be anywhere in RAM – need not be contiguous rewrite satp when switching to another address space/application
how does RISC-V paging hardware translate a va?
need to find the right PTE satp register points to PA of top/L2 PD top 9 bits index L2 PD to get PA of L1 PD next 9 bits index L1 PD to get PA of L0 PD next 9 bits index L0 PD to get PA of PTE PPN from PTE + low-12 from VA
flags in PTE
V, R, W, X, U xv6 uses all of them
what if V bit not set? or store and W bit not set?
“page fault” forces transfer to kernel trap.c in xv6 source kernel can just produce error, kill process in xv6: “usertrap(): unexpected scause … pid=… sepc=… stval=…” or kernel can install a PTE, resume the process e.g. after loading the page of memory from disk
- indirection allows paging h/w to solve many problems e.g. phys memory doesn’t have to be contiguous avoids fragmentation e.g. lazy allocation (a lab) e.g. copy-on-write fork (another lab) many more techniques topic of next lecture
Q: why use virtual memory in kernel?
It is clearly good to have page tables for user processes but why have a page table for the kernel? could the kernel run with using only physical addresses? top-level answer: yes most standard kernels do use virtual addresses why do standard kernels do so? some reasons are lame, some are better, none are fundamental
- the hardware makes it difficult to turn it off e.g. on entering a system call, one would have to disable VM
- the kernel itself can benefit from virtual addresses mark text pages X, but data not (helps tracking down bugs) unmap a page below kernel stack (helps tracking down bugs) map a page both in user and kernel (helps user/kernel transition)
Virtual memory in xv6
- kernel page table
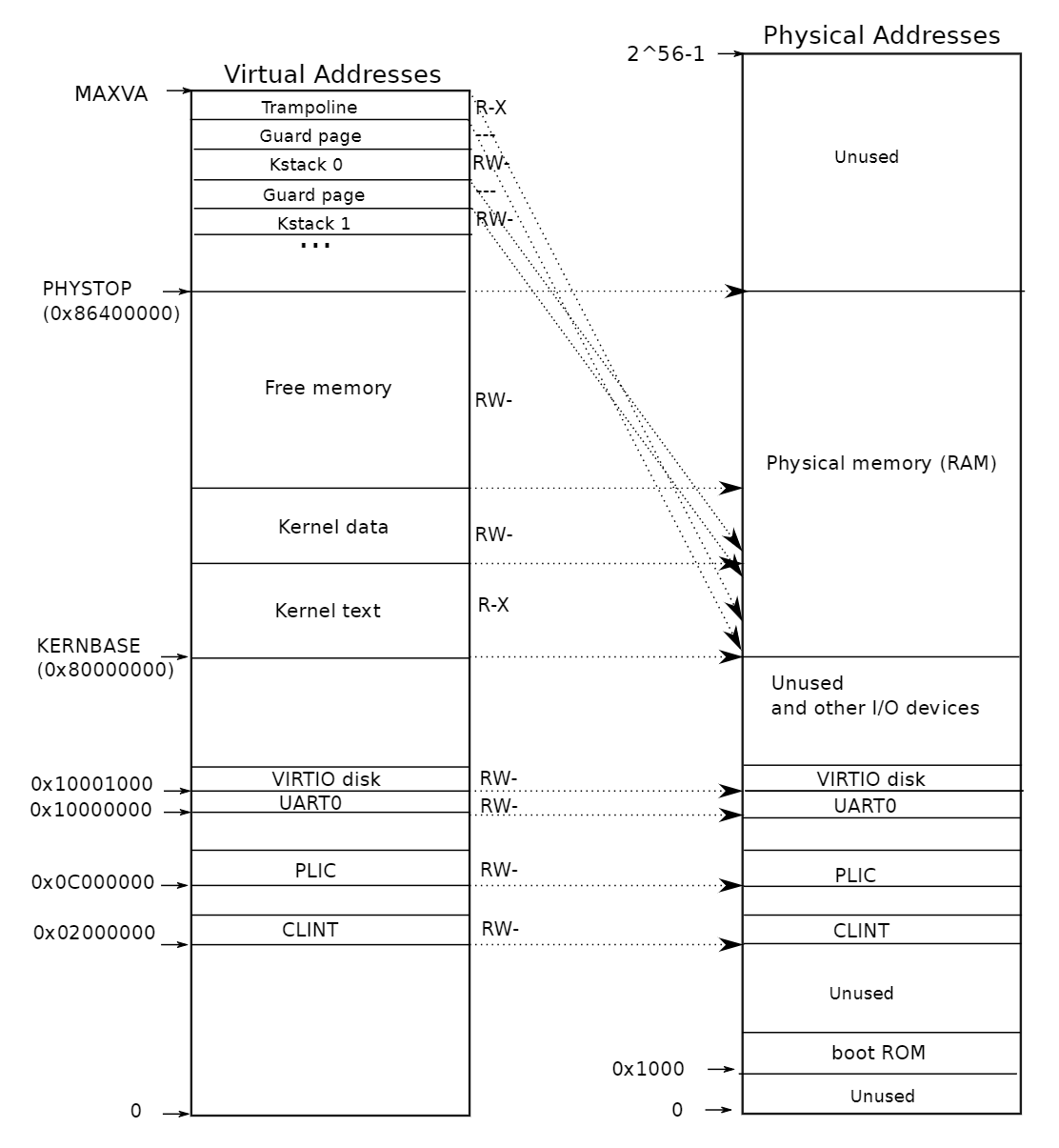
- See figure 3.3 of book simple maping mostly map virtual to physical one-on-one note double-mapping of trampoline note permissions why map devices?
Trampoline 的作用
为内核和用户态之间的切换提供一个统一的入口。由于其在每个进程的页表都映射到相同的物理地址,内核和用户进程都能够在切换过程中使用这段代码,可以确保 :
- 上下文的保存和恢复:保存当前的CPU状态(寄存器,堆栈等),并在返回用户态时恢复。
- 地址空间切换 : 在进程切换时,从用户地址空间切换到内核地址空间,并确保安全。
trampoline成为用户态和内核态之间安全且一致的桥梁。
Each process has its own address space and its own page table
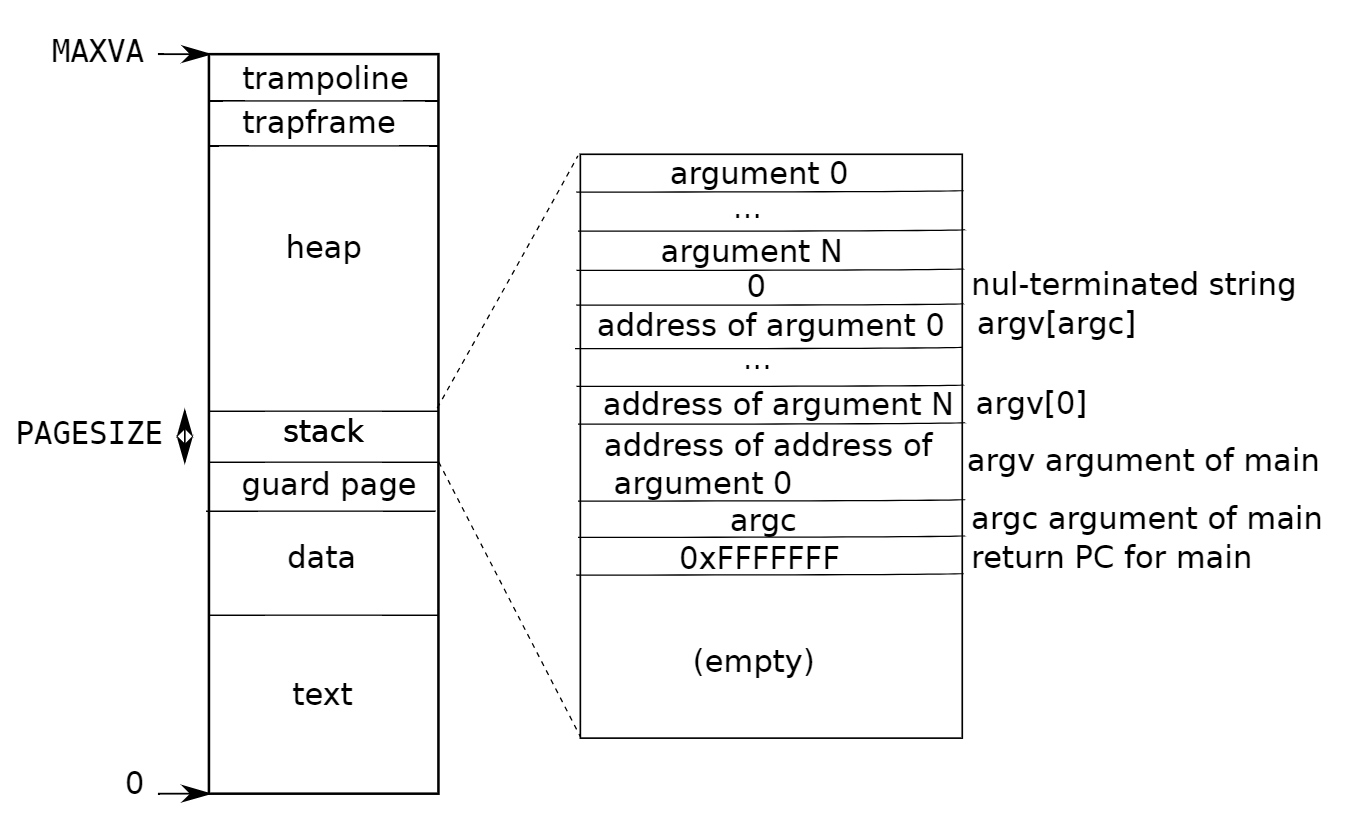
see figure 3.4 of book
note:
-
trampolineandtrapframearen’t writable by user process -
kernel switches page tables (i.e. sets satp) when switching processes
Q: why this address space arrangement?
user virtual addresses start at zero of course user va 0 maps to different pa for each process $16,777,216 GB$ for user heap to grow contiguously but needn’t have contiguous phys mem – no fragmentation problem both kernel and user map trampoline and trapframe page eases transition user -> kernel and back kernel doesn’t map user applications not easy for kernel to r/w user memory need translate user virtual address to kernel virtual address good for isolation (see spectre attacks) easy for kernel to r/w physical memory pa x mapped at va x
Q: does the kernel have to map all of phys mem into its virtual address space?
Code walk through
setup of kernel address space
kvmmap()
// 在内核页表中添加一个映射。
// 仅在启动时使用。
// 该函数不刷新 TLB 或启用分页。
void
kvmmap(uint64 va, uint64 pa, uint64 sz, int perm)
{
// 调用 mappages 函数将虚拟地址 va 映射到物理地址 pa,映射大小为 sz,权限为 perm
if(mappages(kernel_pagetable, va, sz, pa, perm) != 0)
// 如果映射失败,则触发系统错误
panic("kvmmap");
}
Q: what is address 0x10000000 (256M)
$ 0x10000000 = 256 MB$
Q: how much address space does 1 L2 entry cover? (1G)
$512×2 MB=1 GB$
Q: how much address space does 1 L1 entry cover? (2MB)
$512 × 4096B = 2MB$
Q: how much address space does 1 L0 entry cover? (4096)
每个 L0 条目指向一个 4KB 的页,因此每个 L0 条目覆盖 4096 字节的地址空间
print kernel page table
Q: what is size of address space? (512G)
每个L2覆盖 $1GB$, 共覆盖$512GB$
Q: how much memory is used to represent it after 1rst kvmmap()?
($3 pages$)
Q: how many entries is CLINT?
($16 pages$)
Q: how many entries is PLIC?
(1024 pages, two level 1 PDs)
Q: how many pages is kernel text
$ (8 pages)$
Q: how many pages is kernel total
$ (128M = 64 * 2MB)$
Q: Is trampoline mapped twice?
(yes, last entry and direct-mapped, entry [2, 3, 7])
kvminithart();
Q: after executing w_satp() why will the next instruction be sfence_vma()?
mappages()in vm.c
// 为从 va 开始的虚拟地址创建 PTE(页表条目),
// 这些条目引用从 pa 开始的物理地址。
// va 和 size 可能不是页面对齐的。
// 成功返回 0,失败时返回 -1(如果 walk() 无法分配所需的页表页面)。
int
mappages(pagetable_t pagetable, uint64 va, uint64 size, uint64 pa, int perm)
{
uint64 a, last; // 定义变量 a 和 last,用于跟踪当前地址
pte_t *pte; // 定义指针 pte,用于访问页表条目
// 将虚拟地址 va 向下对齐到页面边界
a = PGROUNDDOWN(va);
// 将最后一个虚拟地址向下对齐到页面边界
last = PGROUNDDOWN(va + size - 1);
// 循环创建页表条目
for(;;){
// 获取当前虚拟地址 a 对应的页表条目
if((pte = walk(pagetable, a, 1)) == 0)
return -1; // 如果 walk 失败,返回 -1
// 检查当前页表条目是否已经有效
if(*pte & PTE_V)
panic("remap"); // 如果已经映射,触发错误
// 设置页表条目,映射物理地址 pa,并设置权限和有效位
*pte = PA2PTE(pa) | perm | PTE_V;
// 如果当前地址 a 是最后一个地址,退出循环
if(a == last)
break;
// 继续到下一个页面
a += PGSIZE; // 移动到下一个虚拟地址
pa += PGSIZE; // 移动到下一个物理地址
}
return 0; // 成功创建所有页表条目,返回 0
}
arguments are top PD, va, size, pa, perm
adds mappings from a range of va’s to corresponding pa’s
rounds b/c some uses pass in non-page-aligned addresses
for each page-aligned address in the range
call walkpgdir to find address of PTE
need the PTE’s address (not just content) b/c we want to modify
put the desired pa into the PTE
mark PTE as valid w/ PTE_P
walk()in vm.c
pte_t *
walk(pagetable_t pagetable, uint64 va, int alloc)
{
// 检查虚拟地址是否超过最大虚拟地址
if(va >= MAXVA)
panic("walk");
// 从最高级别的页表开始,逐级向下查找
for(int level = 2; level > 0; level--) {
// 获取当前级别的页表条目指针
pte_t *pte = &pagetable[PX(level, va)];
// 如果页表条目有效
if(*pte & PTE_V) {
// 获取物理地址并进入下一层页表
pagetable = (pagetable_t)PTE2PA(*pte);
} else {
// 如果不分配,或者分配失败,返回0
if(!alloc || (pagetable = (pde_t*)kalloc()) == 0)
return 0;
// 初始化新的页表为0
memset(pagetable, 0, PGSIZE);
// 设置页表条目为新分配的页表的物理地址,标记为有效
*pte = PA2PTE(pagetable) | PTE_V;
}
}
// 返回最低级别页表中对应虚拟地址的页表条目
return &pagetable[PX(0, va)];
}
mimics how the paging h/w finds the PTE for an address
PX extracts the 9 bits at Level level
&pagetable[PX(level, va)] is the address of the relevant PTE
if PTE_V
the relevant page-table page already exists
PTE2PA extracts the PPN from the PDE
if not PTE_V
alloc a page-table page
fill in pte with PPN (using PA2PTE)
now the PTE we want is in the page-table page
procinit()inproc.c
// 在启动时初始化进程表。
void
procinit(void)
{
struct proc *p;
// 初始化进程 ID 锁,以确保对进程 ID 的安全访问。
initlock(&pid_lock, "nextpid");
// 遍历进程表中的每个进程
for(p = proc; p < &proc[NPROC]; p++) {
// 初始化每个进程的锁,以保护进程结构的并发访问。
initlock(&p->lock, "proc");
// 为进程的内核栈分配一页内存。
// 将其映射到高地址内存,并跟随一个无效的保护页。
char *pa = kalloc(); // 分配一页内存
if(pa == 0)
panic("kalloc"); // 如果分配失败,触发系统错误
// 计算该进程内核栈的虚拟地址
uint64 va = KSTACK((int) (p - proc));
// 在内核页表中映射虚拟地址 va 到物理地址 pa,大小为 PGSIZE,权限为可读和可写
kvmmap(va, (uint64)pa, PGSIZE, PTE_R | PTE_W);
// 将计算出的虚拟地址保存到进程结构中
p->kstack = va;
}
// 初始化虚拟内存管理相关的硬件设置
kvminithart();
}
alloc a page for each kernel stack with a guard page
setup user address space
allocproc(): allocates empty top-level page table
// 在进程表中查找一个 UNUSED 状态的进程。
// 如果找到,初始化所需的状态以在内核中运行,并返回时持有 p->lock。
// 如果没有空闲的进程,或内存分配失败,返回 0。
static struct proc*
allocproc(void)
{
struct proc *p;
// 遍历进程表中的每个进程
for(p = proc; p < &proc[NPROC]; p++) {
acquire(&p->lock); // 获取进程的锁以安全访问其状态
if(p->state == UNUSED) { // 检查进程状态是否为 UNUSED
goto found; // 找到空闲进程,跳转到初始化部分
} else {
release(&p->lock); // 如果不是 UNUSED,释放锁并继续下一个进程
}
}
// 如果没有找到空闲进程,返回 0
return 0;
found:
// 分配一个新的进程 ID
p->pid = allocpid();
// 为进程分配一个 trapframe 页面,用于处理系统调用和中断
if((p->trapframe = (struct trapframe *)kalloc()) == 0) {
release(&p->lock); // 分配失败,释放锁
return 0; // 返回 0 表示失败
}
// 创建一个空的用户页面表
p->pagetable = proc_pagetable(p);
if(p->pagetable == 0) { // 检查页面表分配是否成功
freeproc(p); // 如果分配失败,释放进程资源
release(&p->lock); // 释放锁
return 0; // 返回 0 表示失败
}
// 设置新的上下文,以在 forkret 处开始执行,
// forkret 会返回到用户空间。
memset(&p->context, 0, sizeof(p->context)); // 清零上下文结构
p->context.ra = (uint64)forkret; // 设置返回地址为 forkret 函数
p->context.sp = p->kstack + PGSIZE; // 设置堆栈指针到内核栈的顶部
return p; // 返回分配和初始化的进程
}
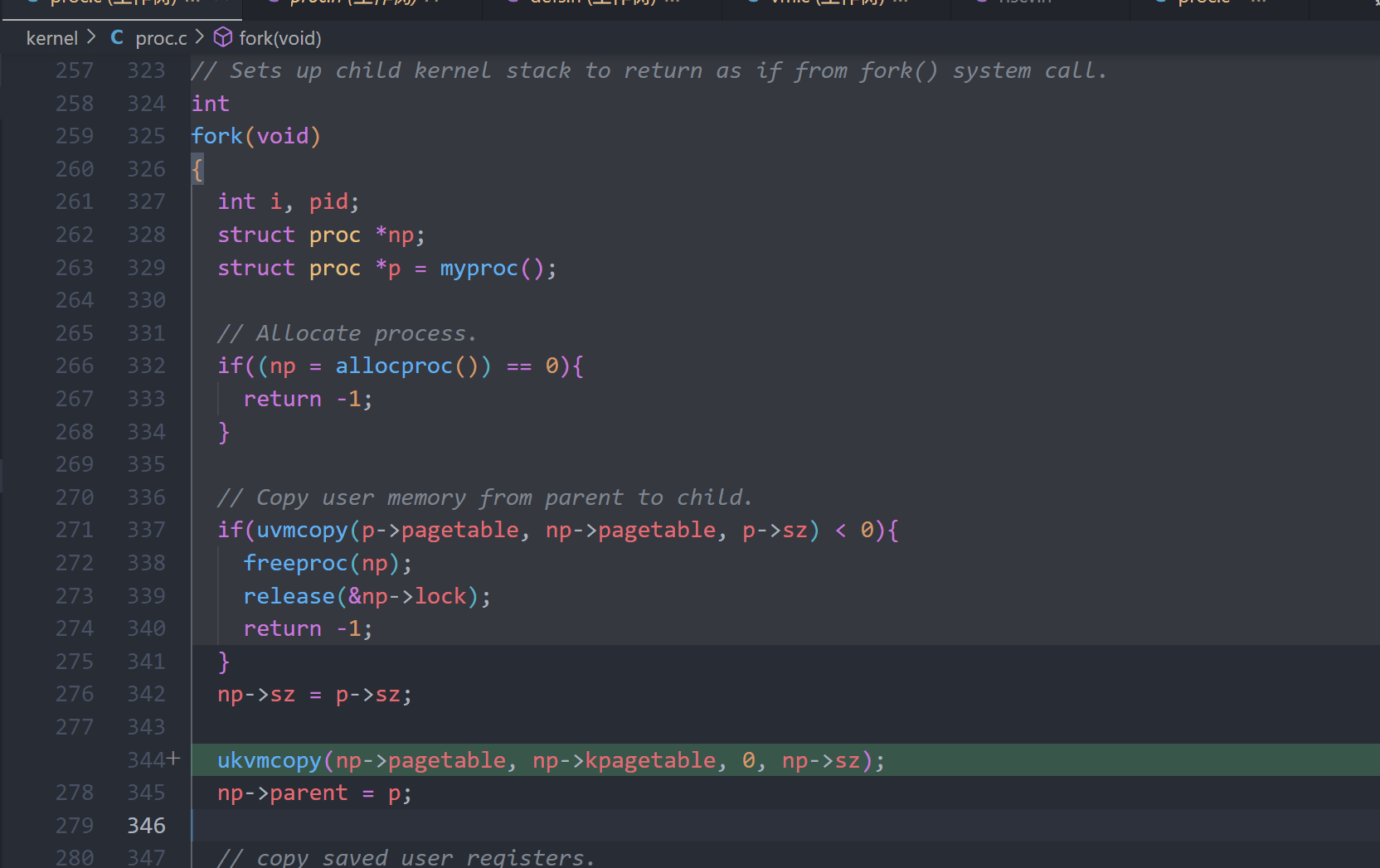
fork(): uvmcopy()
// 根据父进程的页表,将其内存复制到子进程的页表。
// 复制页表和物理内存。
// 成功返回 0,失败返回 -1。
// 在失败时释放已分配的页面。
int
uvmcopy(pagetable_t old, pagetable_t new, uint64 sz)
{
pte_t *pte; // 页表条目的指针
uint64 pa, i; // 物理地址和循环变量
uint flags; // 页表条目的标志位
// 遍历从 0 到 sz 的所有页面
for(i = 0; i < sz; i += PGSIZE){
// 获取旧页表中对应虚拟地址的页表条目
if((pte = walk(old, i, 0)) == 0)
panic("uvmcopy: pte should exist"); // 如果未找到页表条目,触发错误
// 检查页表条目是否有效
if((*pte & PTE_V) == 0)
panic("uvmcopy: page not present"); // 如果页面不存在,触发错误
// 获取物理地址
pa = PTE2PA(*pte);
// 清除写权限标志,以便进行写时复制(Copy-On-Write)
*pte &= (~PTE_W); // 清除 PTE_W
*pte |= (PTE_C); // 设置 PTE_C,标记此页面为 Copy-On-Write
// 获取当前页表条目的其他标志
flags = PTE_FLAGS(*pte);
// 在新页表中映射原来的物理地址
if (mappages(new, i, PGSIZE, pa, flags) != 0)
{
goto err; // 如果映射失败,跳转到错误处理
}
// 增加物理页面的引用计数
kincre((void *)pa);
}
return 0; // 成功完成复制,返回 0
err:
// 释放在新页表中已分配的页面
uvmunmap(new, 0, i / PGSIZE, 1);
return -1; // 返回 -1 表示失败
}
exec(): replace proc’s page table with a new one
// 执行指定路径的程序,设置新的用户栈并准备参数。
// 成功返回程序的参数个数,失败返回 -1。
int
exec(char *path, char **argv)
{
char *s, *last; // 字符串指针,用于处理路径
int i, off; // 循环变量和偏移量
uint64 argc, sz = 0, sp, ustack[MAXARG+1], stackbase; // 参数计数、内存大小、栈指针、用户栈数组和栈基地址
struct elfhdr elf; // ELF 头结构
struct inode *ip; // 文件节点指针
struct proghdr ph; // 程序头结构
pagetable_t pagetable = 0, oldpagetable; // 新旧页表
struct proc *p = myproc(); // 获取当前进程结构
begin_op(); // 开始文件操作
// 查找程序路径对应的 inode
if((ip = namei(path)) == 0){
end_op(); // 结束文件操作
return -1; // 找不到文件,返回 -1
}
ilock(ip); // 锁定 inode
// 检查 ELF 头
if(readi(ip, 0, (uint64)&elf, 0, sizeof(elf)) != sizeof(elf))
goto bad; // 读取 ELF 头失败,跳转到错误处理
if(elf.magic != ELF_MAGIC)
goto bad; // 检查 ELF 魔法数,若不匹配则跳转到错误处理
// 获取当前进程的页表
if((pagetable = proc_pagetable(p)) == 0)
goto bad; // 获取页表失败,跳转到错误处理
// 从 ELF 文件加载程序到内存
for(i = 0, off = elf.phoff; i < elf.phnum; i++, off += sizeof(ph)){
// 读取程序头
if(readi(ip, 0, (uint64)&ph, off, sizeof(ph)) != sizeof(ph))
goto bad; // 读取失败,跳转到错误处理
if(ph.type != ELF_PROG_LOAD)
continue; // 仅处理加载类型的程序头
if(ph.memsz < ph.filesz)
goto bad; // 内存大小小于文件大小,跳转到错误处理
if(ph.vaddr + ph.memsz < ph.vaddr)
goto bad; // 地址溢出,跳转到错误处理
uint64 sz1;
// 为加载的段分配内存
if((sz1 = uvmalloc(pagetable, sz, ph.vaddr + ph.memsz)) == 0)
goto bad; // 内存分配失败,跳转到错误处理
sz = sz1; // 更新分配大小
// 检查段的虚拟地址是否对齐
if(ph.vaddr % PGSIZE != 0)
goto bad; // 虚拟地址未对齐,跳转到错误处理
// 从文件中加载段到内存
if(loadseg(pagetable, ph.vaddr, ip, ph.off, ph.filesz) < 0)
goto bad; // 加载段失败,跳转到错误处理
}
iunlockput(ip); // 解锁并释放 inode
end_op(); // 结束文件操作
ip = 0; // 清空 inode 指针
p = myproc(); // 再次获取当前进程结构
uint64 oldsz = p->sz; // 保存旧的程序大小
// 在下一个页边界分配两个页面
// 使用第二个页面作为用户栈
sz = PGROUNDUP(sz); // 将大小向上对齐到页边界
uint64 sz1;
if((sz1 = uvmalloc(pagetable, sz, sz + 2*PGSIZE)) == 0)
goto bad; // 内存分配失败,跳转到错误处理
sz = sz1; // 更新分配大小
uvmclear(pagetable, sz - 2 * PGSIZE); // 清除栈底的页面内容
sp = sz; // 设置栈指针
stackbase = sp - PGSIZE; // 设置栈基地址
// 将参数字符串推入栈,并准备栈的其他部分
for(argc = 0; argv[argc]; argc++) {
if(argc >= MAXARG)
goto bad; // 超过最大参数数量,跳转到错误处理
sp -= strlen(argv[argc]) + 1; // 为参数字符串分配空间
sp -= sp % 16; // 确保栈指针是 16 字节对齐
if(sp < stackbase)
goto bad; // 栈指针超出栈基,跳转到错误处理
if(copyout(pagetable, sp, argv[argc], strlen(argv[argc]) + 1) < 0)
goto bad; // 将参数字符串复制到用户栈失败,跳转到错误处理
ustack[argc] = sp; // 保存参数字符串的地址
}
ustack[argc] = 0; // 以 0 结束参数数组
// 将 argv[] 指针数组推入栈
sp -= (argc + 1) * sizeof(uint64); // 为 argv 指针数组分配空间
sp -= sp % 16; // 确保栈指针是 16 字节对齐
if(sp < stackbase)
goto bad; // 栈指针超出栈基,跳转到错误处理
if(copyout(pagetable, sp, (char *)ustack, (argc + 1) * sizeof(uint64)) < 0)
goto bad; // 复制 argv 指针数组失败,跳转到错误处理
// 准备用户主函数的参数 (argc, argv)
// argc 将通过系统调用返回值放入 a0 中
p->trapframe->a1 = sp; // 将栈指针赋值给 trapframe
// 保存程序名称以便调试
for(last = s = path; *s; s++)
if(*s == '/')
last = s + 1; // 找到路径中的最后一个斜杠
safestrcpy(p->name, last, sizeof(p->name)); // 复制程序名称
// 提交用户映像
oldpagetable = p->pagetable; // 保存旧的页表
p->pagetable = pagetable; // 更新当前进程的页表
p->sz = sz; // 更新进程的内存大小
p->trapframe->epc = elf.entry; // 设置初始程序计数器为 ELF 入口点
p->trapframe->sp = sp; // 设置初始栈指针
proc_freepagetable(oldpagetable, oldsz); // 释放旧的页表
return argc; // 返回参数个数,放入 a0,作为 main(argc, argv) 的第一个参数
bad:
// 错误处理部分
if(pagetable)
proc_freepagetable(pagetable, sz); // 释放已分配的页表
if(ip){
iunlockput(ip); // 解锁并释放 inode
end_op(); // 结束文件操作
}
return -1; // 返回 -1 表示失败
}
uvmalloc()
loadseg()
// 将程序段加载到指定的页表中,虚拟地址为 va。
// va 必须是页对齐的,且从 va 到 va+sz 的页必须已经映射。
// 成功时返回 0,失败时返回 -1。
static int
loadseg(pagetable_t pagetable, uint64 va, struct inode *ip, uint offset, uint sz)
{
uint i, n; // 循环变量 i 和每页要读取的字节数 n
uint64 pa; // 映射到的物理地址
// 检查虚拟地址是否是页对齐的
if((va % PGSIZE) != 0)
panic("loadseg: va must be page aligned");
// 遍历每个页,从虚拟地址 va 开始,直到加载的大小 sz
for(i = 0; i < sz; i += PGSIZE){
// 获取当前虚拟地址对应的物理地址
pa = walkaddr(pagetable, va + i);
// 如果物理地址为 0,表示对应的页不存在,触发 panic
if(pa == 0)
panic("loadseg: address should exist");
// 确定要读取的字节数
if(sz - i < PGSIZE)
n = sz - i; // 如果剩余的字节数小于一页,则只读取剩余的字节
else
n = PGSIZE; // 否则读取一整页
// 从 inode 中读取数据到物理内存中
if(readi(ip, 0, (uint64)pa, offset+i, n) != n)
return -1; // 如果读取的字节数不等于 n,返回 -1 表示失败
}
return 0; // 成功加载所有页,返回 0
}
print user page table for sh
Q: what is entry 2?
a process calls sbrk(n) to ask for n more bytes of heap memory
user/umalloc.c calls sbrk() to get memory for the allocator
each process has a size
kernel adds new memory at process’s end, increases size
sbrk() allocates physical memory (RAM)
maps it into the process’s page table
returns the starting address of the new memory
growproc()inproc.c
// 增加或减少用户内存 n 字节。
// 成功时返回 0,失败时返回 -1。
int
growproc(int n)
{
uint sz; // 当前进程的内存大小
struct proc *p = myproc(); // 获取当前进程结构
sz = p->sz; // 获取当前进程的内存大小
if(n > 0){ // 如果 n 为正,表示增加内存
// 尝试分配新的内存空间
if((sz = uvmalloc(p->pagetable, sz, sz + n)) == 0) {
// 如果内存分配失败,返回 -1
return -1;
}
} else if(n < 0){ // 如果 n 为负,表示减少内存
// 尝试释放内存
sz = uvmdealloc(p->pagetable, sz, sz + n);
// 注意:此处没有检查 uvmdealloc 的返回值,假设其成功
}
p->sz = sz; // 更新当前进程的内存大小
return 0; // 返回 0 表示成功
}
proc->sz is the process’s current size
uvmalloc() does most of the work
when switching to user space satp will be loaded with updated page table
uvmalloc()invm.c
// 为进程分配页表项和物理内存,将进程从 oldsz 扩展到 newsz。
// newsz 不需要页对齐。成功时返回新大小,失败时返回 0。
uint64
uvmalloc(pagetable_t pagetable, uint64 oldsz, uint64 newsz)
{
char *mem; // 用于存储分配的内存指针
uint64 a; // 循环变量,用于遍历分配的内存地址
// 如果新的大小小于旧的大小,直接返回旧的大小
if(newsz < oldsz)
return oldsz;
// 将旧大小向上对齐到下一个页边界
oldsz = PGROUNDUP(oldsz);
// 从旧大小开始,逐页分配内存直到新的大小
for(a = oldsz; a < newsz; a += PGSIZE){
// 分配一页物理内存
mem = kalloc();
if(mem == 0){
// 如果内存分配失败,释放已经分配的内存并返回 0
uvmdealloc(pagetable, a, oldsz);
return 0;
}
// 将分配的内存初始化为 0
memset(mem, 0, PGSIZE);
// 将分配的物理内存映射到进程的虚拟地址空间
if(mappages(pagetable, a, PGSIZE, (uint64)mem, PTE_W|PTE_X|PTE_R|PTE_U) != 0){
// 如果映射失败,释放物理内存并释放已分配的内存
kfree(mem);
uvmdealloc(pagetable, a, oldsz);
return 0;
}
}
// 如果所有的内存都成功分配和映射,返回新的大小
return newsz;
}
why PGROUNDUP?
arguments to mappages()…
Lab: page tables
Print a page table (easy)
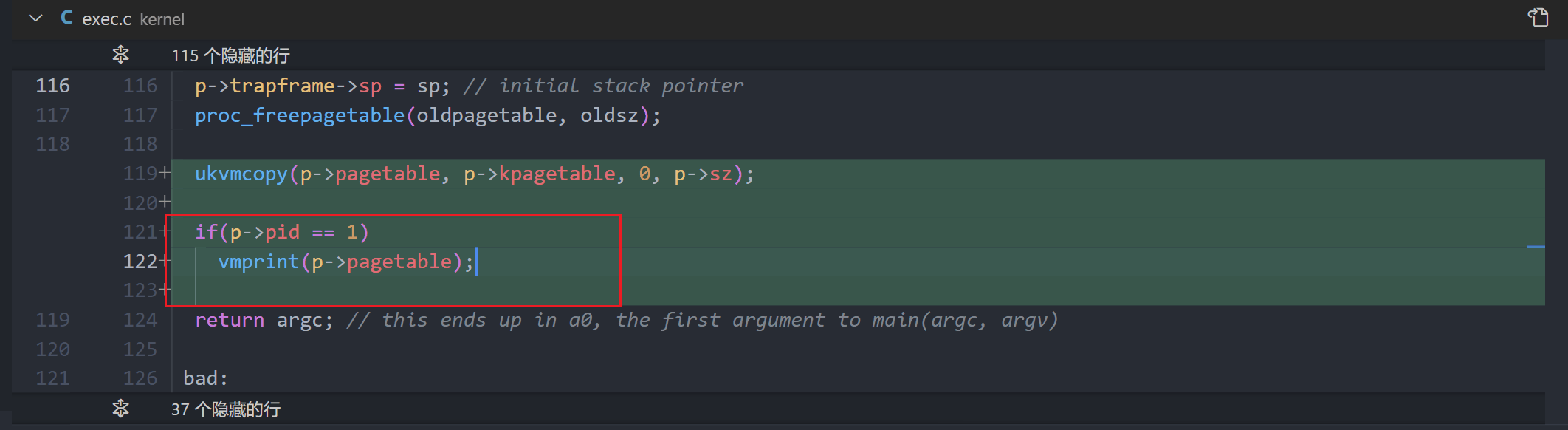
Define a function called vmprint(). It should take a pagetable_t argument, and print that pagetable in the format described below. Insert if(p->pid==1) vmprint(p->pagetable) in exec.c just before the return argc, to print the first process’s page table. You receive full credit for this assignment if you pass the pte printout test of make grade.
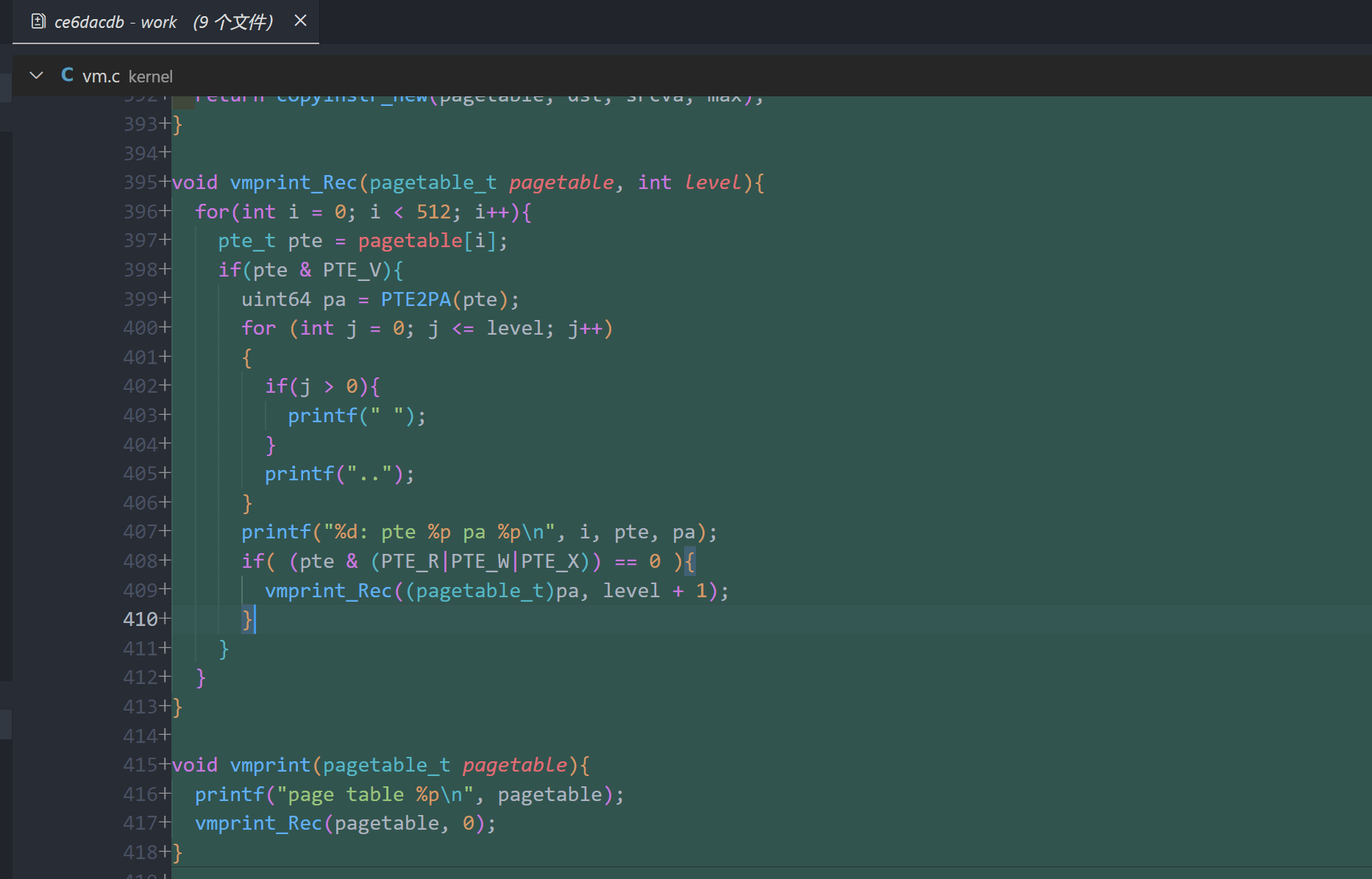
void
vmprint_rec(pagetable_t pagetable, int level)
{
for (int i = 0; i < 512; i++) {
pte_t pte = pagetable[i];
if (pte & PTE_V) {
uint64 pa = PTE2PA(pte);
for (int j = 0; j <= level; j++) {
if(j > 0){
printf(" ");
}
printf("..");
}
printf("%d: pte %p pa %p\n", i, pte, pa);
if ((pte & (PTE_R | PTE_W | PTE_X)) == 0) {
// Recursively print next level page table
vmprint_rec((pagetable_t)pa, level + 1);
}
}
}
}
void
vmprint(pagetable_t pagetable)
{
printf("page table %p\n", pagetable);
vmprint_rec(pagetable, 0);
}
pid = 1代表init进程,即第一个启动的用户级进程,它负责派生其他进程并为系统提供基本服务。
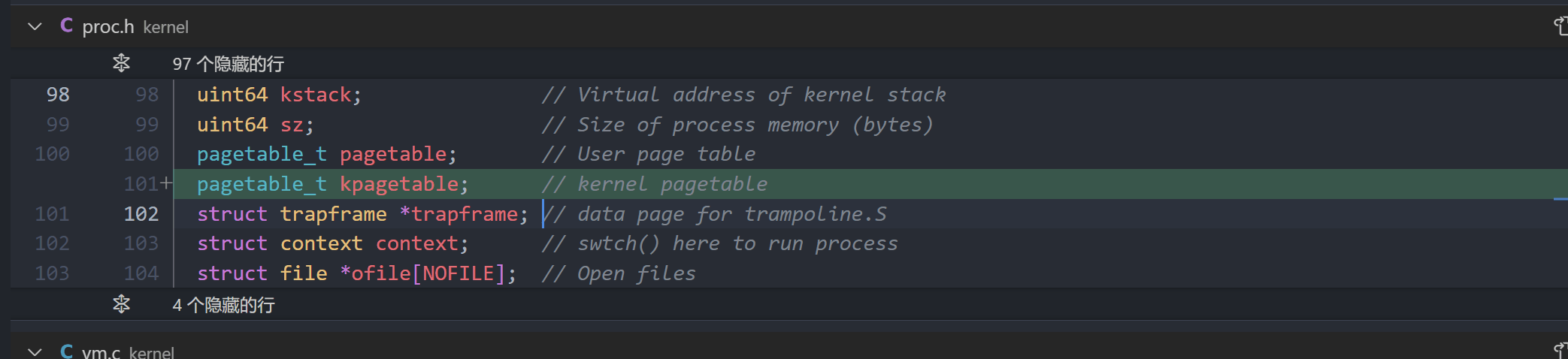
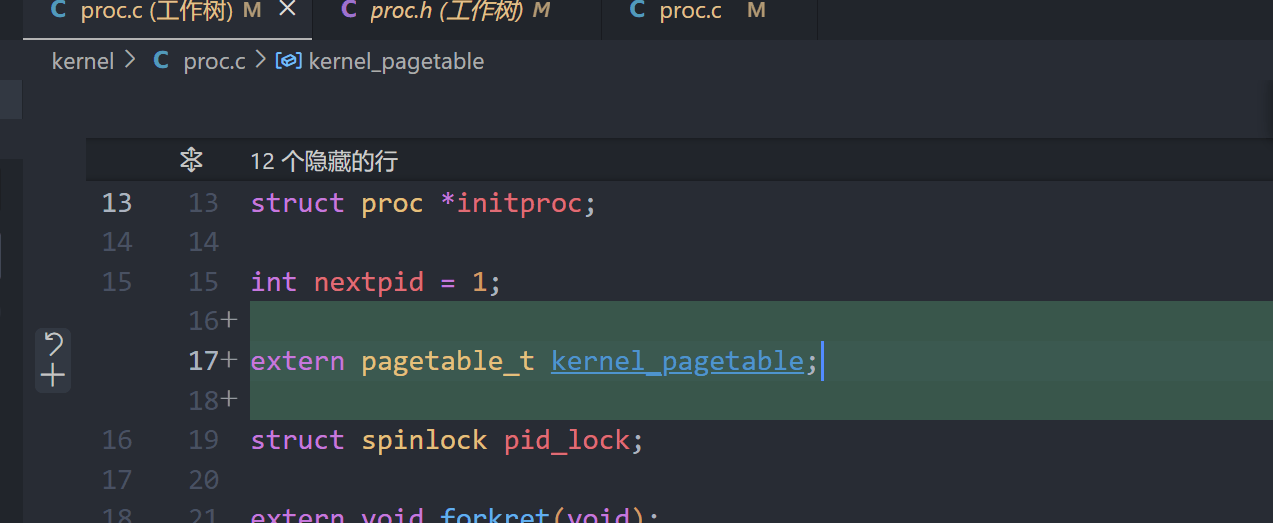
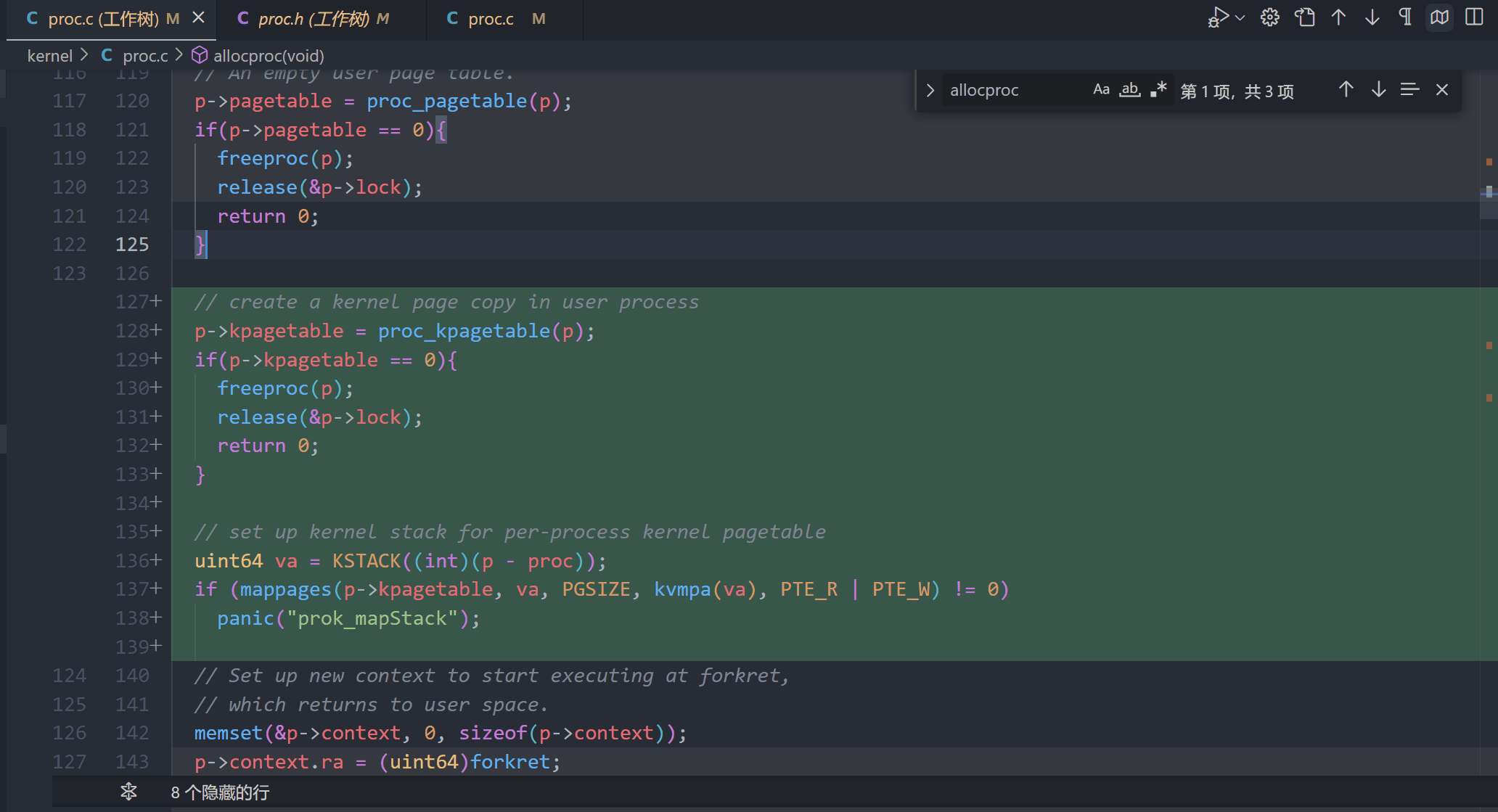
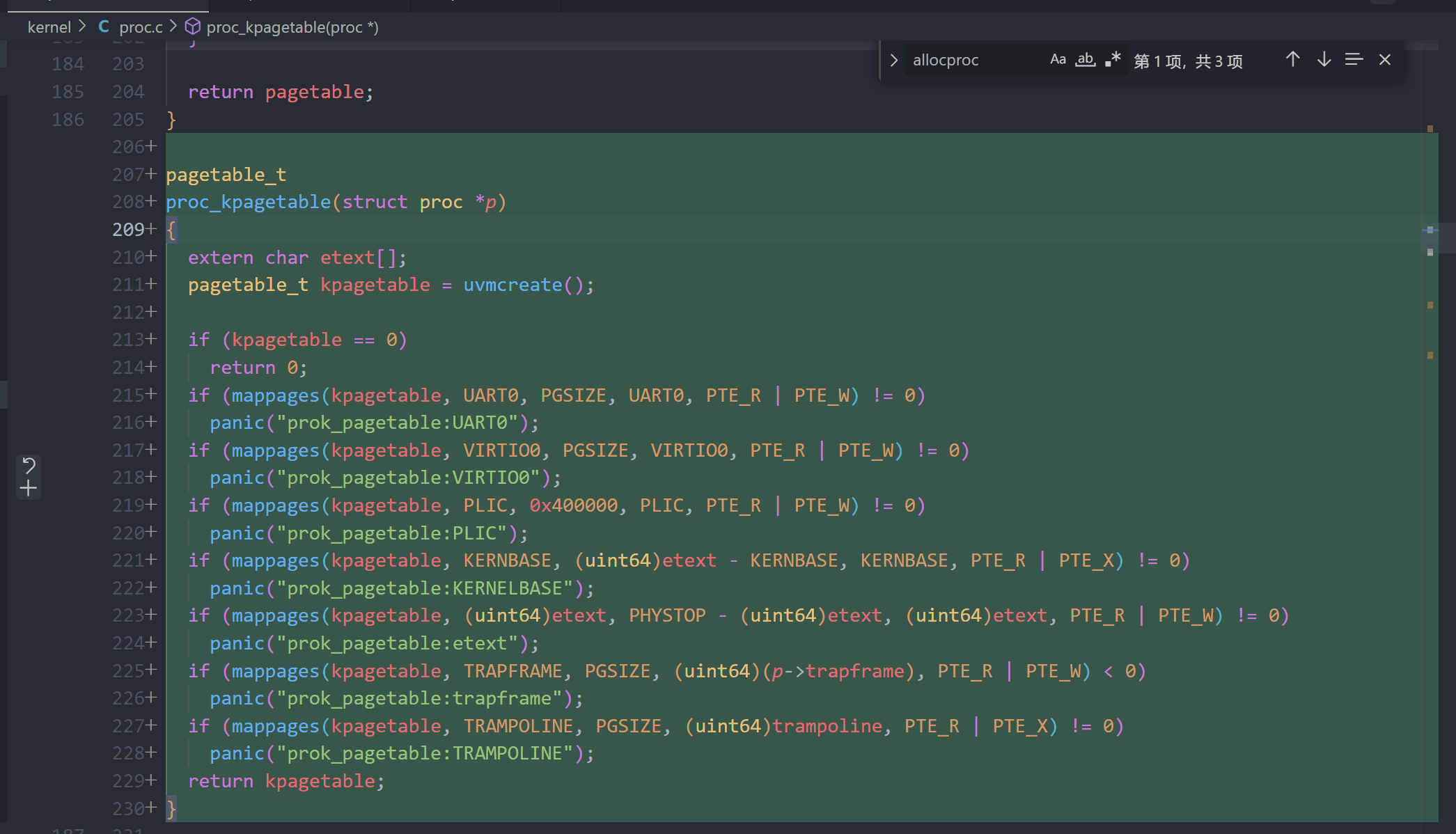
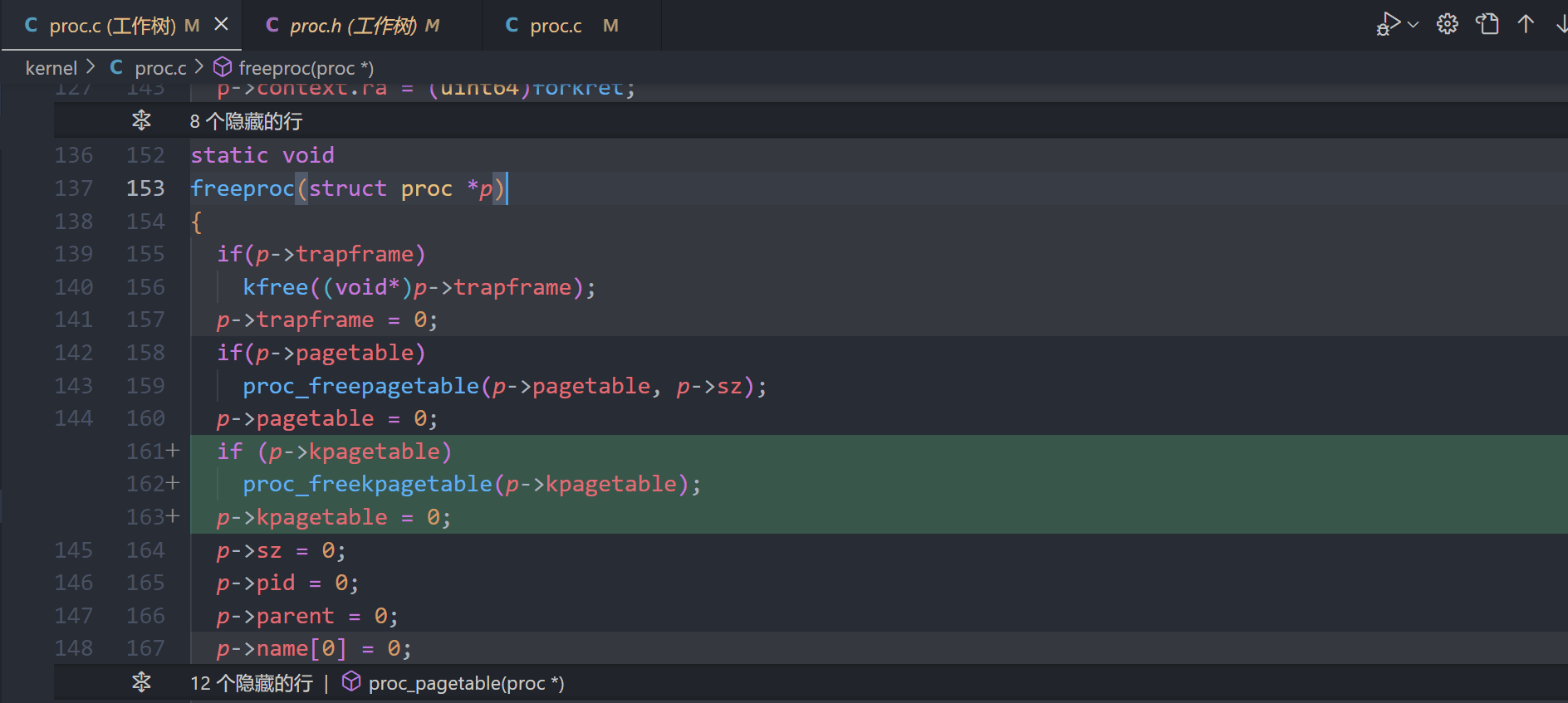
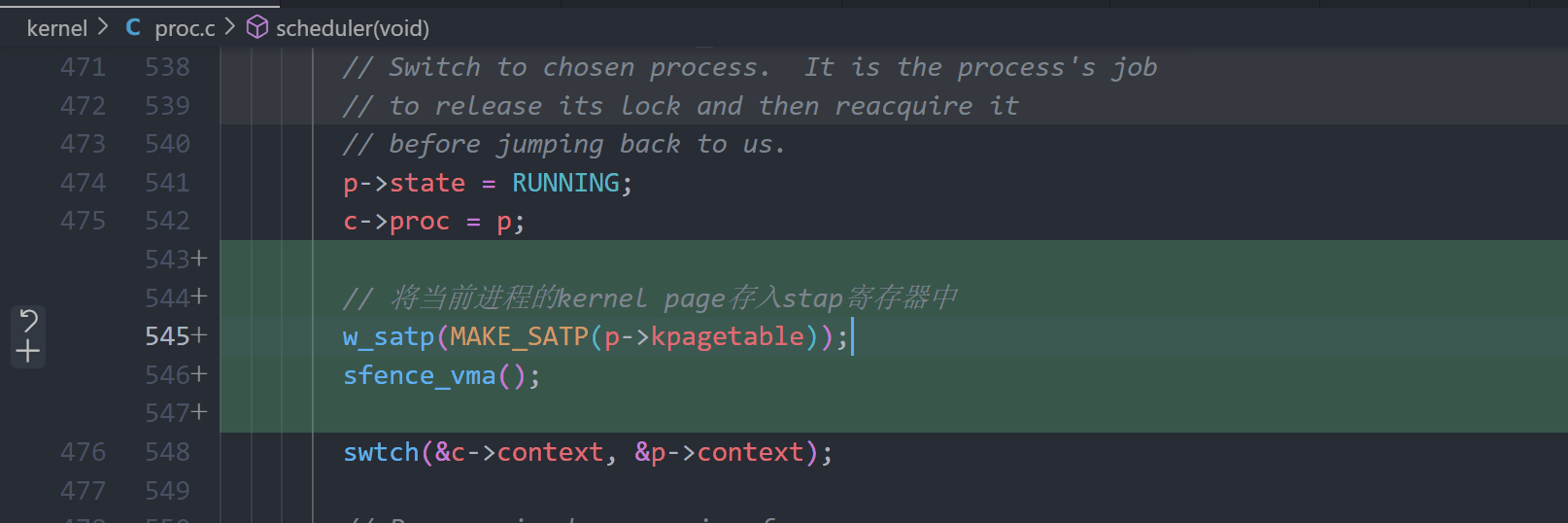
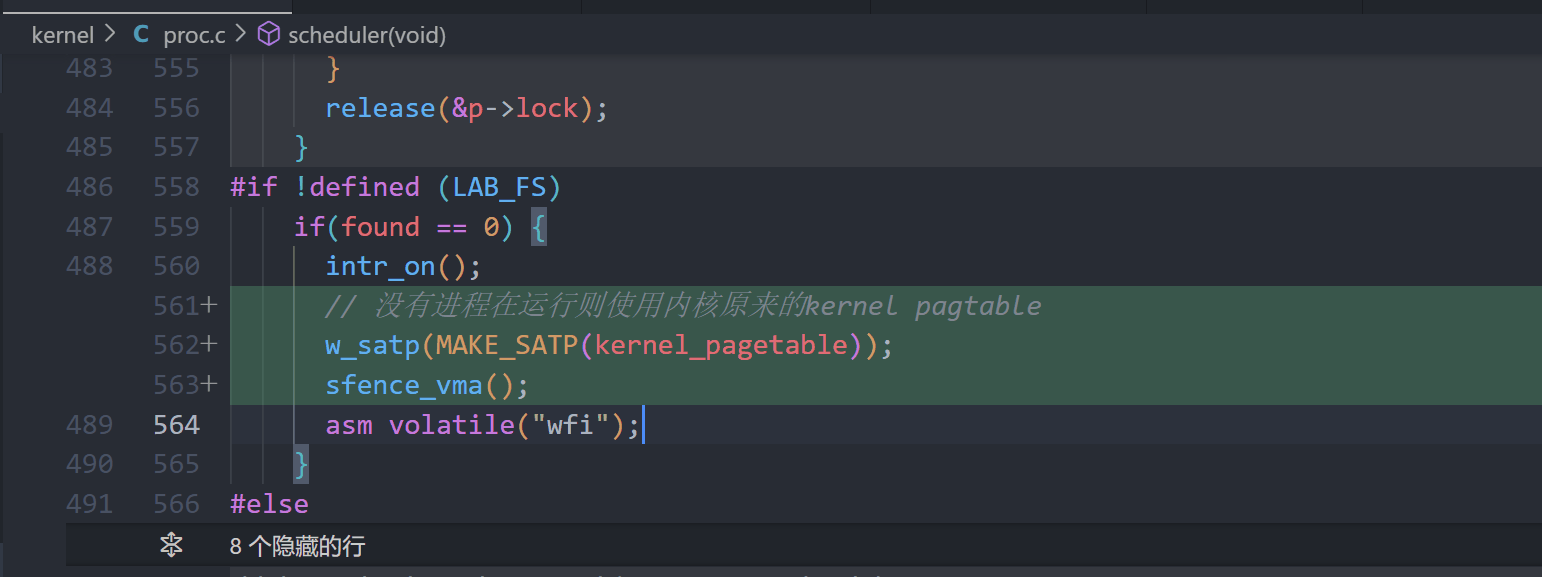
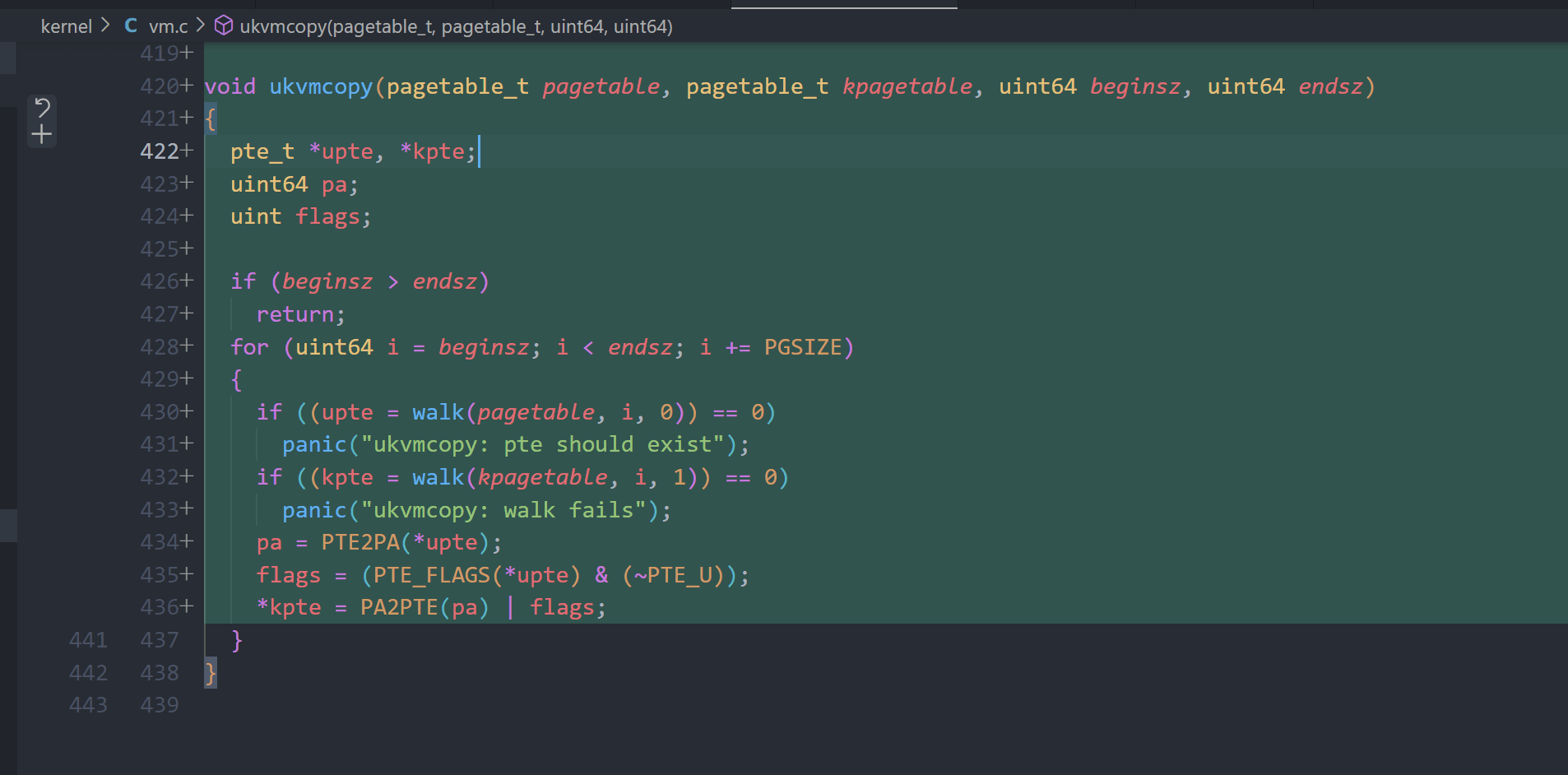
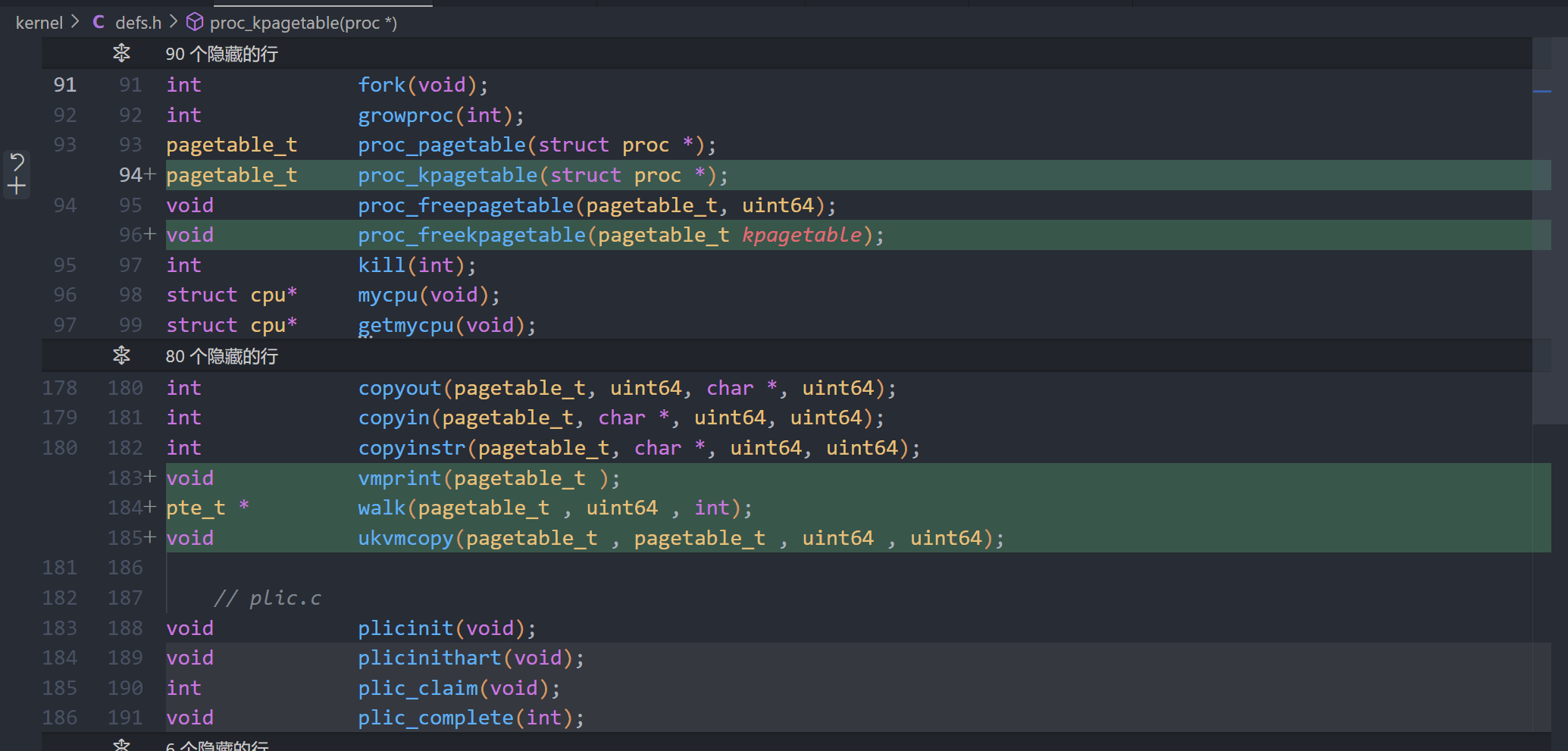
A kernel page table per process (hard)
proc.h
proc.c
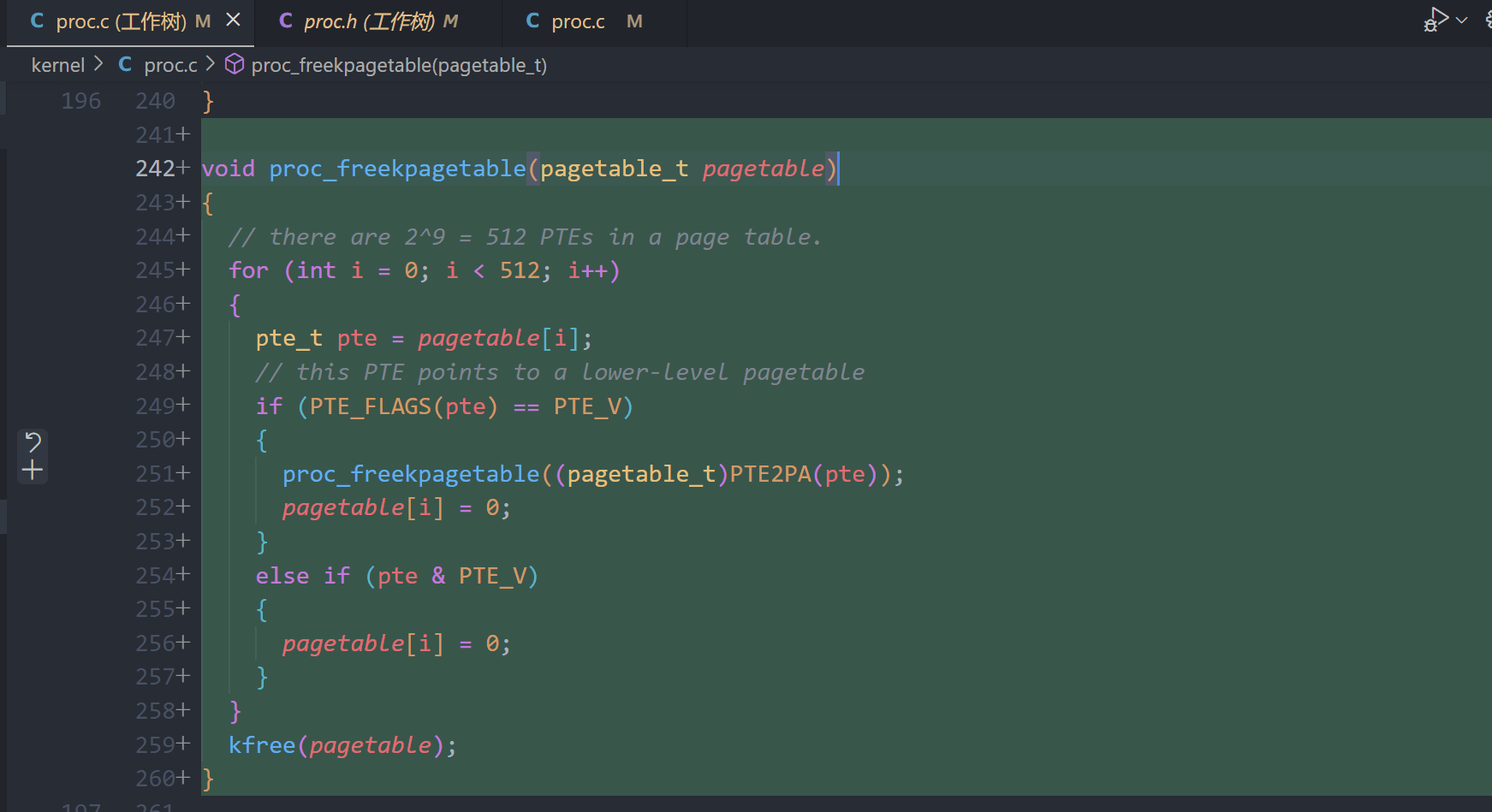
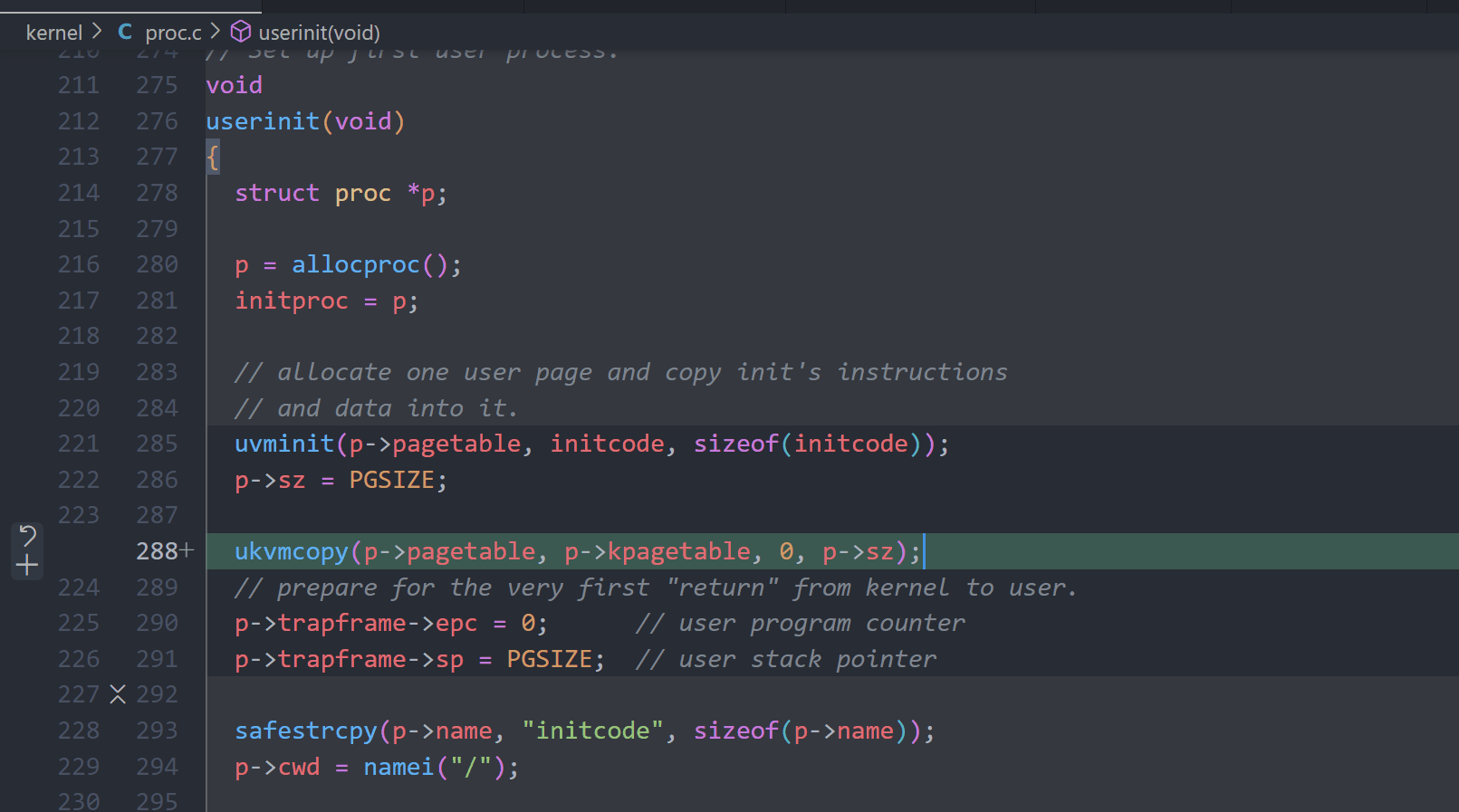
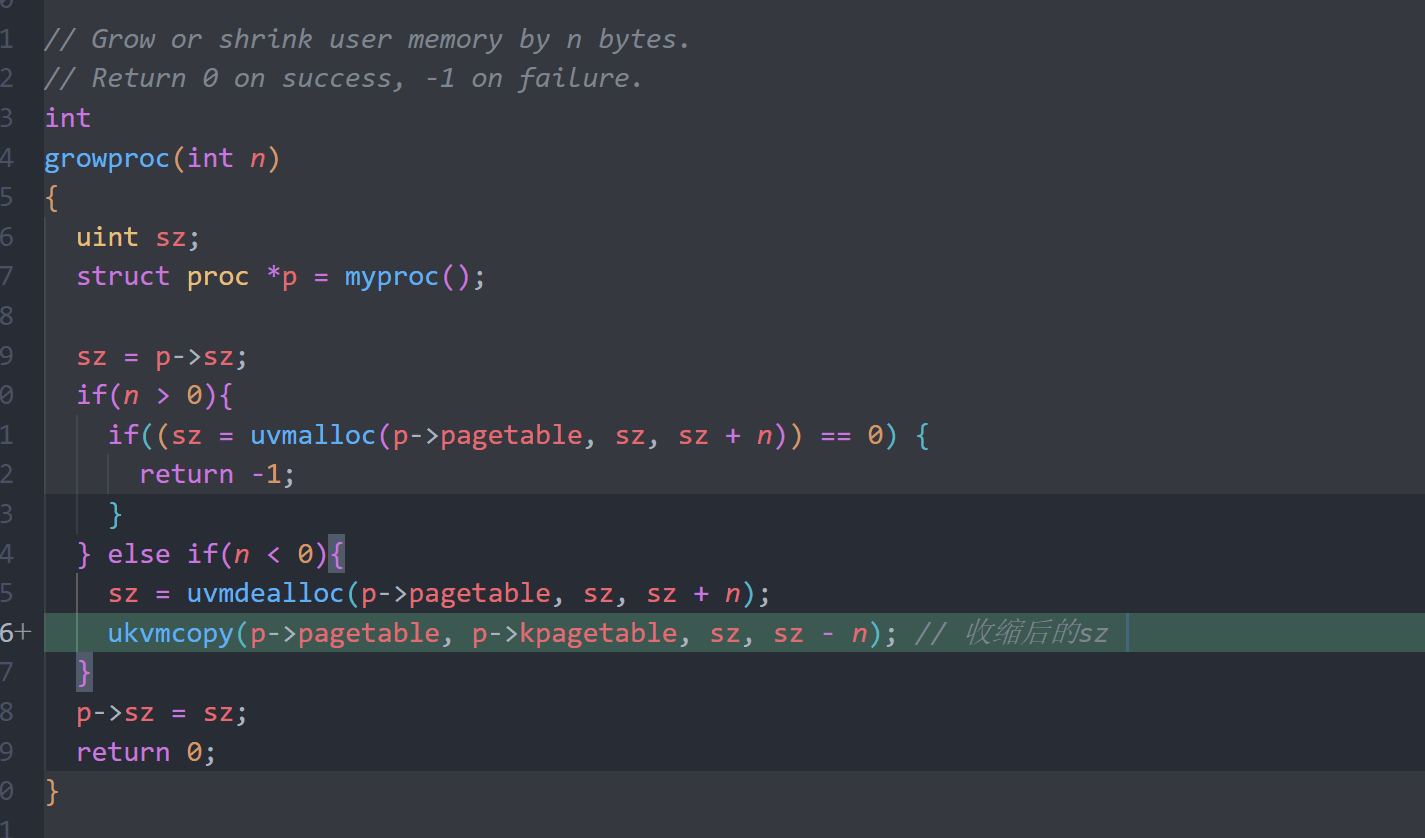
vm.c
defs.h
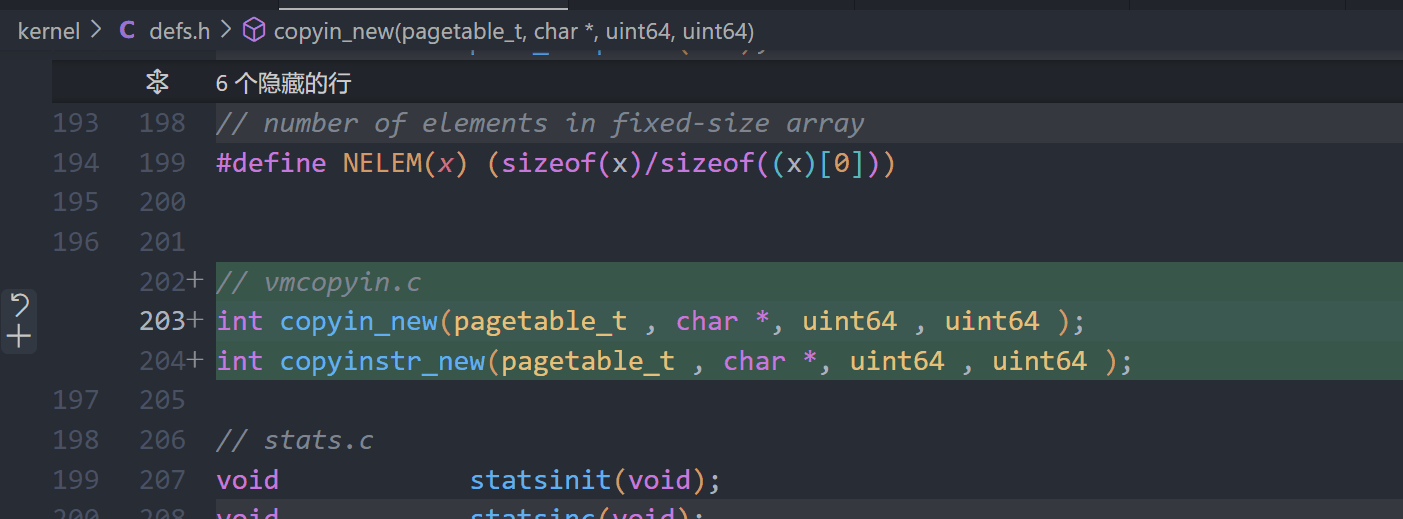
Simplify copyin/copyinstr (hard)
defs.h
vm.c